🤖 AI - 怎么理解大模型
作为大模型的使用者,不需要了解太多内部实现细节。可以将模型当做黑盒,理解其输入和输出。
chat/completions
以 OpenAP 的 API 为例:
https://api.openai.com/v1/chat/completions
接口名:chat/completions
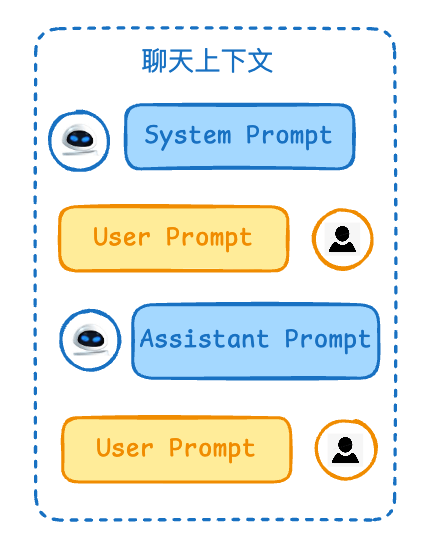
chat:聊天是一个会话,有上下文。
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'有哪些 role:
- Developer
- System
- User
- Assistant
- Tool
- Function
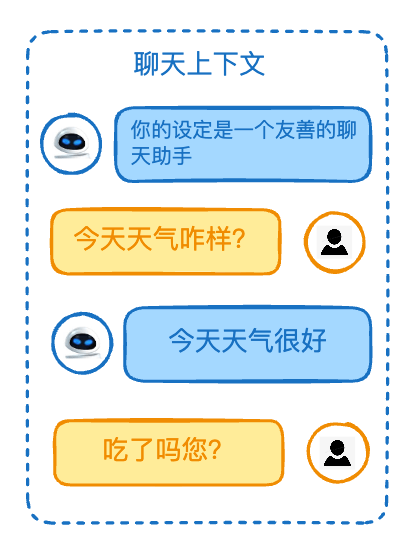
🤔 Q:为什么模型能记住我们之前聊天的内容?
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"messages": [
{
"role": "system",
"content": "你是一个友好的个人助理,可以回答我生活相关的问题"
},
{
"role": "user",
"content": "今天天气怎么样?"
},
{
"role": "assistant",
"content": "今天天气很暖和"
},
{
"role": "user",
"content": "我应该带伞么?"
}
]
}'
chat/completions 中的 completions
我们输入的 messages 在模型内部会怎么处理呢?
文本会转换成模型可理解的符号(文本 -> token -> token IDs),再对符号进行补全。
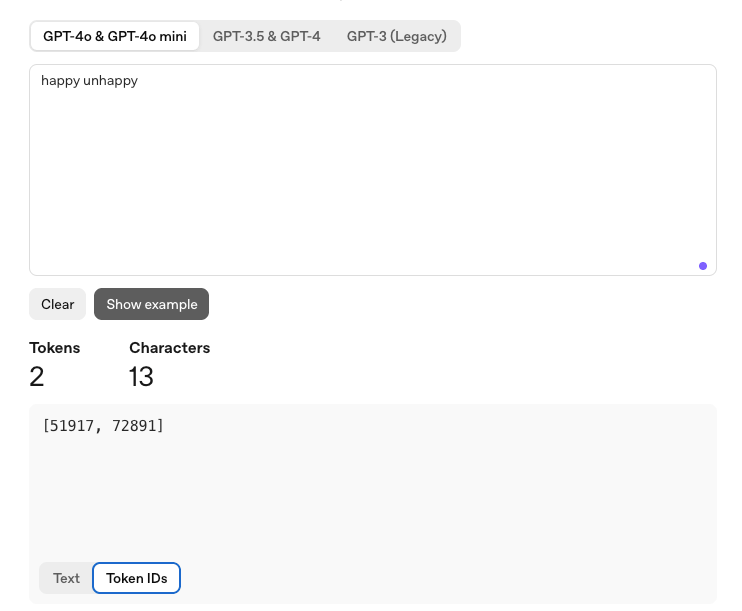
token 不等于字符或单词。
- 不是按单词拆分:happy unhappy
- 不同上下文中拆分不一样:This is my backpack : backpack
不同语言,token 表达效率不同。
英文:The weather is good today
中文:今天天气真好
日文:今日の天気はいいです
西班牙语:El tiempo está bueno hoy
我们可以使用用更少的 token 来表达同样意思的语言。
不同模型使用的分词器也不同。
流浪地球计划,共分为5步:
第一步,用地球发动机使地球停止转动,将发动机喷口固定在地球运行的反方向;
第二步,全功率开动行星发动机,使地球加速到逃逸速度,飞出太阳系;
第三步,在外太空继续加速,飞向比邻星;
第四步,在中途使地球重新自转,调转发动机方向,开始减速;
第五步,地球泊入比邻星轨道,成为这颗恒星的卫星。以 OpenAI GPT 为例,一般规律:
- 1 个 token 约等于 4 个英文字符,大概 3/4 个单词。
- 1 个 token 接近 0.7 个中文汉字
对于 Claude3.5-sonnet-200k ,200k 的 token:
- 200k token = 150k 单词
- 标准短篇小说 5000 单词
- 上下文极限情况可以容纳 30 篇短篇小说
符号(token)补全
参数 Temperature、Top_p、Frequency Penalty、presence_penalty 如何影响补全效果?
例如:“我喜欢吃” -> 预测下一个 token
可能的 token 及其概率:
- “饭” (0.3)
- “菜” (0.2)
- “水果” (0.15)
- “零食” (0.1)
- …其他选项
Temperature
0 ~ 2,调整概率分布的差异。
- 低温:强化高概率选项,减少选择的多样性
- 高温:使概率分布更平缓,增加选择的多样性
Temperature = 0.2时:
"饭" (0.8)
"菜" (0.1)
"水果" (0.05)
...
Temperature = 1.5时:
"饭" (0.3)
"菜" (0.25)
"水果" (0.23)
...Top_p 核采样
设定累计概率阈值,从高概率到低概率依次选择 token,直到总和达到设定值。
Top_p = 0.75时:
选择:"饭"(0.3) + "菜"(0.2) + "水果"(0.15) + "零食"(0.1) = 0.75
其他选项被排除Frequency Penalty 概率惩罚
-2 ~ 2,降低已出现的 token 再次出现的概率,迫使模型选择新的表达方式。
如果"喜欢"已经出现过:
原始概率:"喜欢"(0.3) → 惩罚后:(0.1)
我喜欢吃饭,我也爱吃烧烤Presence Penalty 存在惩罚
-2 ~ 2,降低已出现主题的相关 token 的概率。
例如,如果已经讨论过 “食物” 的主题,相关 token 概率都会被降低,促使模型转向新主题。
我喜欢吃饭, -> 我也喜欢吃烧烤
0.7:我喜欢吃放,周末常去夜市撸串 (引入周末和夜市场景)
1:我喜欢吃放,假期约上朋友去大排档,美食总能让生活充满乐趣(引入新场景、人物、情感)
-1:我喜欢吃饭吃面吃烧烤