# 🧠 AI - Claude Code 记忆系统 CLAUDE.md
Claude Code 记忆系统 CLAUDE.md。
和 AI 协作,你有没有这样的经历?
```markdown
第一次对话:
你:帮我写一个用户登录接口
Claude:好的,这是一个基础的登录接口...(使用 Express + JavaScript)
你:我们项目用的是 Fastify 和 TypeScript
Claude:好的,让我重新写...
第二次对话:
你:帮我写一个订单创建接口
Claude:好的,这是一个基础的订单接口...(又用 Express + JavaScript)
你:(崩溃)我们用 Fastify 和 TypeScript!
```
如果 Claude Code 不记得我的项目使用什么技术栈、什么编码规范、什么团队规范,每次新对话都让我从零开始 --- 那这种 "失忆症" 让人抓狂。
 CLAUDE.md 就是治疗这种失忆症的药 --- 它是一份给 Claude 的 "项目入职手册",Claude 每次开始新对话时,就会自动阅读这份手册,了解项目背景,明确它在干活时应该遵循的一系列底层规则。
### Claude Code 记忆系统
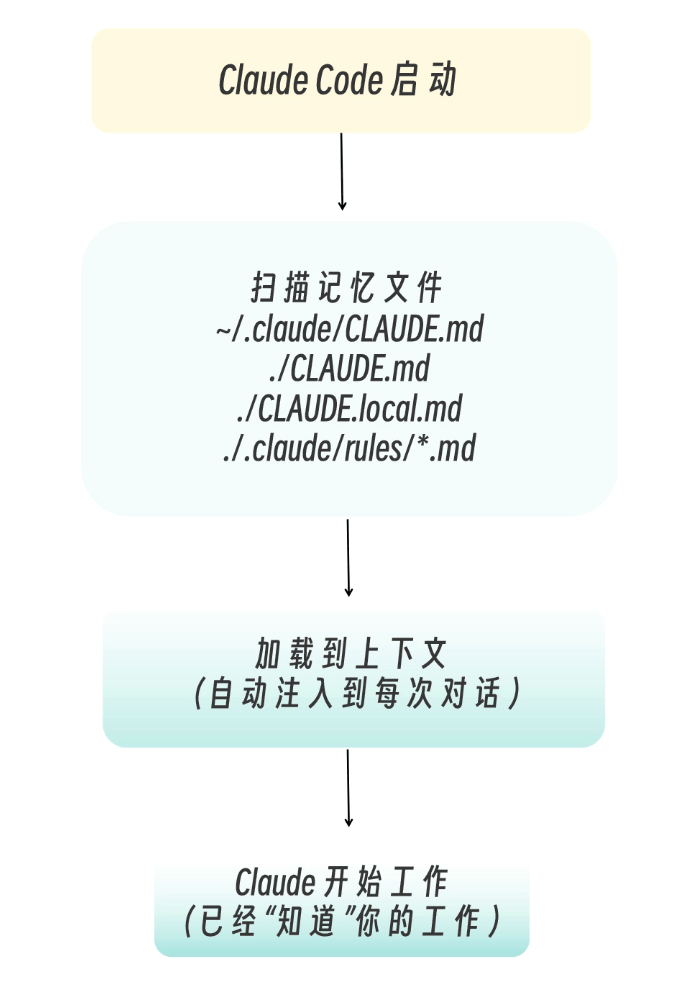
当你在项目根目录启动 Claude Code 时,发生的 "记忆系统初始化" 过程如下图所示:
CLAUDE.md 就是治疗这种失忆症的药 --- 它是一份给 Claude 的 "项目入职手册",Claude 每次开始新对话时,就会自动阅读这份手册,了解项目背景,明确它在干活时应该遵循的一系列底层规则。
### Claude Code 记忆系统
当你在项目根目录启动 Claude Code 时,发生的 "记忆系统初始化" 过程如下图所示:
 Claude 有多种方式获取项目相关知识,它们的区别如下:
Claude 有多种方式获取项目相关知识,它们的区别如下:
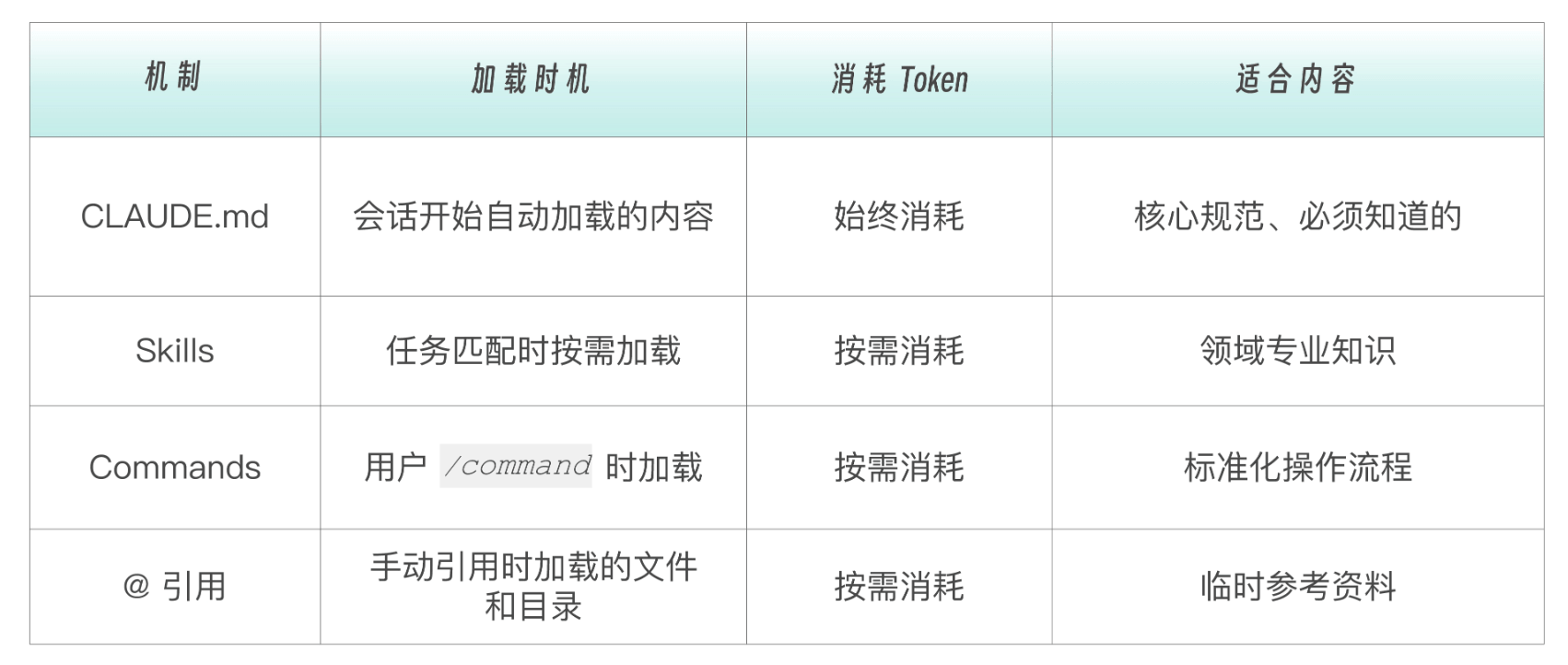 CLAUDE.md 的内容在每次开始新对话时都会加载,所以要精简,把 "每次都需要" 的内容放在这里,把 "偶尔需要" 的内容放到 Skills 或文档里。
### Claude Code 记忆架构
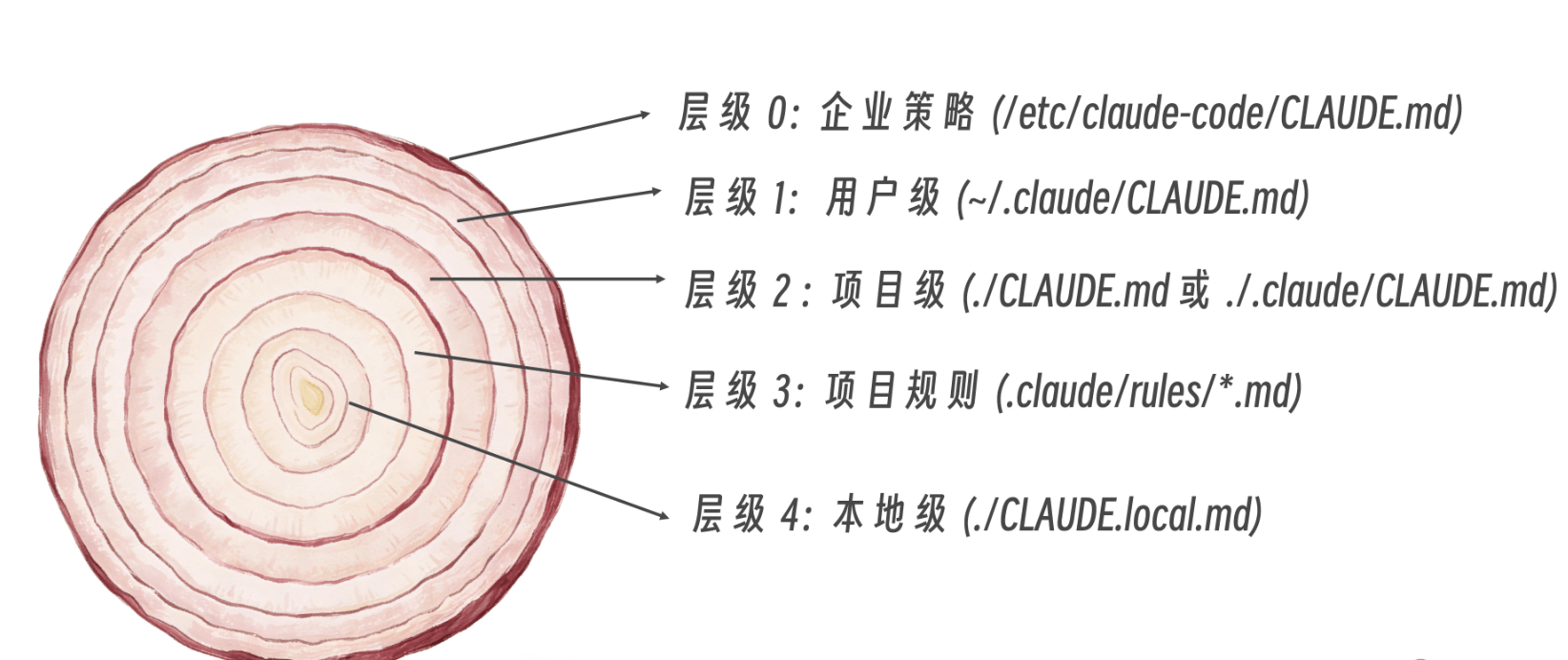
Claude 支持五个层级的记忆,就像洋葱一样,从外到内,按层级结构组织 --- 高层级的文件优先加载,为底层文件提供基础。
CLAUDE.md 的内容在每次开始新对话时都会加载,所以要精简,把 "每次都需要" 的内容放在这里,把 "偶尔需要" 的内容放到 Skills 或文档里。
### Claude Code 记忆架构
Claude 支持五个层级的记忆,就像洋葱一样,从外到内,按层级结构组织 --- 高层级的文件优先加载,为底层文件提供基础。
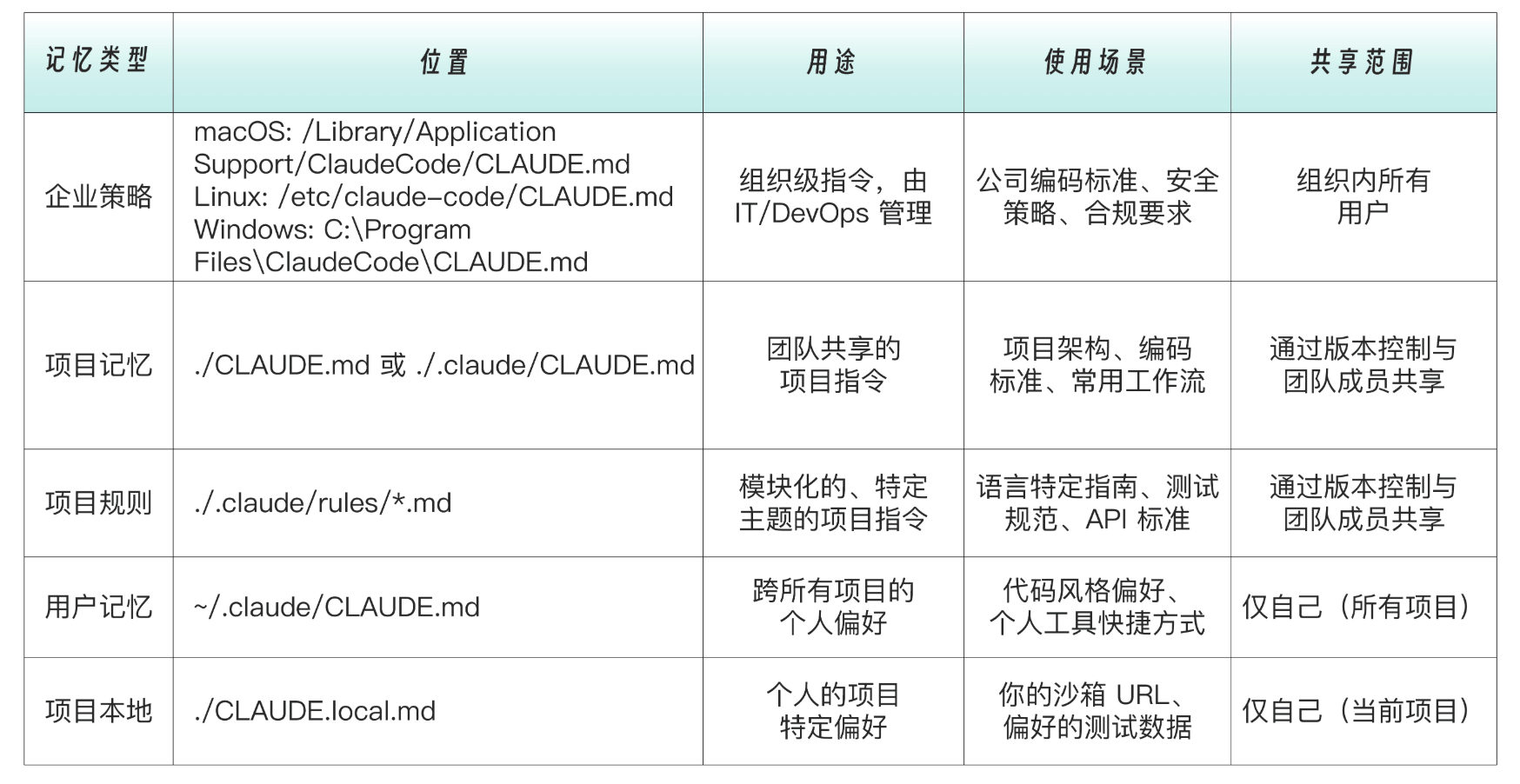
 记忆类型表如下:
记忆类型表如下:
 #### 企业策略级记忆设定
企业策略级记忆设定的作用是阻值范围内的指令,由 IT/DevOps 统一管理和部署组织。适合内容是公司编码标准、安全策略、合规要求以及禁止使用的库或模式。通过配置管理系统部署,确保在所有开发者机器上一致分发。
位置:
- macOS: /Library/Application Support/ClaudeCode/CLAUDE.md
- Linux: /etc/claude-code/CLAUDE.md
- Windows: C:\Program Files\ClaudeCode\CLAUDE.md
示例:
```markdown
# 公司开发策略
## 安全要求
- 禁止在代码中硬编码任何秘钥或敏感信息
- 所有 API 调用必须使用 HTTPS
- 用户输入必须经过验证和清理
## 合规要求
- 所有日志必须排除 PII(个人身份信息)
- 数据库连接必须使用加密传输
## 禁止项
- 禁止使用未经审批的第三方库
- 禁止直接访问生产数据库
```
如果你是个人或小团队,可以直接跳过企业级设定这一层,不影响任何使用。
#### 用户级内容设定
用户级内容设定承载的是你的全局偏好,如个人代码风格、沟通语言设置、通用工作习惯等。
位置:~/.claude/CLAUDE.md
示例:
```markdown
# 个人偏好
## 沟通方式
- 使用中文回复
- 代码注释使用英文
- 解释简洁直接,不要过多铺垫
## 通用代码风格
- 缩进使用 2 个空格
- 优先使用 async/await
- 变量命名使用 camelCase
- 常量命名使用 UPPER_SNAKE_CASE
## 我的常用工具
- 包管理器:pnpm
- 编辑器:VS Code
- 终端:zsh
```
用户级记忆会被项目级覆盖,如果你个人喜欢 2 个空格缩进,但项目要求 4 个空格,那就用 4 个空格。
#### 项目级团队共享规范
团队共享规范是团队共享的项目知识,应该提交到 Git。适合存放的内容包括技术栈、项目架构、编码规范、重要的设计决策和常用命令等。
位置:项目根目录的 ./CLAUDE.md
示例:
```markdown
# 项目:订单服务 API
## 技术栈
- Node.js 20 + TypeScript
- Fastify(Web 框架)
- Prisma(ORM)
- PostgreSQL + Redis
- Zod(数据验证)
## 目录结构
src/
├── routes/ # 路由定义
├── controllers/ # 请求处理
├── services/ # 业务逻辑
├── repositories/ # 数据访问
├── schemas/ # Zod schemas
└── types/ # 类型定义
## 编码规范
- TypeScript strict 模式
- 禁止使用 any,使用 unknown + 类型守卫
- 所有 API 端点必须有 Zod schema 验证
- 业务错误使用自定义 Error 类
## 常用命令
- pnpm dev - 启动开发服务器
- pnpm test - 运行测试
- pnpm prisma migrate dev - 运行数据库迁移
```
#### 本地个人工作空间
个人工作空间用于记载个人工作笔记,不提交到 Git,适合内容包括本地环境配置、个人调试技巧、当前工作备注、敏感信息(测试账号等)。
位置:项目根目录的 ./CLAUDE.local.md
示例:
```markdown
# 本地开发笔记
## 我的环境
- 本地 API:http://localhost:3000
- 测试数据库:order_service_dev
- Redis:localhost:6379
## 测试账号
- admin@test.com / test123
- user@test.com / test123
## 当前工作
- 正在重构支付模块
- 参考 PR #234 的讨论
- 周五前完成
## 调试技巧
- 订单状态机日志: LOG_LEVEL=debug pnpm dev
- 查看 Redis 缓存: redis-cli KEYS "order:\*"
```
记得把 CLAUDE.local.md 加入到 .gitignore!
```
echo "CLAUDE.local.md" >> .gitignore
```
#### 规则目录:分类组织
Rules 是按主题组织的规则文件,支持条件作用域,适合场景包括 CLAUDE.md 变得太长时、不同文件类型需要不同规范时、以及前后端分离的项目。
位置:.claude/rules/\*.md
目录结构:
```markdown
.claude/
└── rules/
├── typescript.md # TypeScript 规范
├── testing.md # 测试规范
├── api-design.md # API 设计规范
└── security.md # 安全规范
```
示例:.claude/rules/testing.md
````markdown
---
paths:
- "src/**/*.test.ts"
- "tests/**/*.ts"
---
# 测试规范
## 命名
- 单元测试: `*.test.ts`
- 集成测试: `*.integration.test.ts`
## 结构
使用 Arrange-Act-Assert 模式:
```typescript
describe("OrderService", () => {
describe("createOrder", () => {
it("should create order when stock is available", async () => {
// Arrange
const mockProduct = createMockProduct({ stock: 10 });
// Act
const order = await orderService.createOrder(mockProduct.id, 1);
// Assert
expect(order.status).toBe("created");
});
});
});
```
## 覆盖率要求
- 业务逻辑: > 80%
- 工具函数: > 90%
- 路由/控制器: 可以较低
````
此处的关键特性是 paths 字段,让这个规则只在编辑测试文件时生效,不会浪费其他场景的上下文空间。
### 编写高效的 CLAUDE.md
CLAUDE.md 写得好不好,直接决定了 Claude 是靠谱同事,还是每次都要重新培训的实习生。
下面来讨论 CLAUDE.md 编写需要遵循的核心原则,了解怎么写,才值得每次都被加载到上下文中。
#### 核心原则 1:Less is More
CLAUDE.md 的每一行,都会在每一次对话开始时被自动注入到上下文中。这意味着一件事:冗余不是无害的,是持续消耗的。所以保持精简不是建议,而是必须。
#### 核心原则 2:具体优于泛泛
先来看一个常见的,但几乎没有任何效果的写法:
```markdown
# 项目规范
## 代码质量
- 请写出高质量的代码。
- 代码应该是可读的。
- 使用有意义的变量名。
- 保持代码整洁。
- 遵循最佳实践。
```
这些内容没有一句是错的,但问题在于 --- Claude 本来就知道这些。它们不会改变 Claude 的任何决策,只会白白占用上下文空间。这些内容对人类尚且含糊,对模型来说,更是几乎等于什么都没说。
真正有价值的 CLAUDE.md,应该是这样:
````markdown
# 项目规范
## TypeScript
- 使用 `interface` 定义对象结构,`type` 用于联合类型
- 禁止 `any`,使用 `unknown` + 类型守卫
- 函数参数 > 3 个时,使用对象参数
## 错误处理
```typescript
// 业务错误
throw new BusinessError("ORDER_NOT_FOUND", "订单不存在");
// 验证错误(Zod 自动抛出)
const data = orderSchema.parse(input);
// controller 中不要 try-catch
// 由全局错误中间件统一处理
```
````
后者不是模糊要求 "要高质量",而是给出了如何做才算高质量;不是 "注意错误处理",而是给出了具体的错误模型;不是 "抽象描述",而是给出了可直接模仿的代码形态。
#### 核心原则 3:WHY/WHAT/HOW
一份真正 "能用" 的 CLAUDE.md,通常都在回答三个问题,不是一次性回答,而是在关键地方给出明确指引。
- WHY - 为什么要这样做?
```markdown
## 为什么使用 Zod?
- TypeScript 只有编译时类型检查
- API 输入需要运行时验证
- Zod 可以同时生成 TS 类型和验证逻辑
- 错误信息自动生成,对用户友好
```
这一部分的作用不是让 Claude “记住一个库”,而是让它理解背后的决策逻辑。当 Claude 明白了为什么,它在面对相似但不完全相同的场景时,才更有可能做出一致的判断。
- WHAT - 具体要做什么,不要做什么?
```markdown
## 数据库操作规范
- 所有查询通过 Prisma ORM
- 复杂查询封装在 `src/repositories/`
- 禁止在 controller/service 中直接写 SQL
- 事务使用 `prisma.$transaction()`
```
这一部分的重点是边界。什么是允许的,什么是禁止的,决策应该发生在哪一层?对于 Claude 来说,这比 "最佳实践" 四个字重要得多。
- HOW - 按什么步骤去做?
```markdown
## 创建新 API 端点
1. 在 `src/schemas/` 创建请求/响应 Zod schema
2. 在 `src/routes/` 添加路由定义
3. 在 `src/controllers/` 实现请求处理
4. 在 `src/services/` 实现业务逻辑
5. 在 `tests/` 添加测试用例
示例参考: `src/routes/orders.ts`
```
当步骤清晰、路径明确、还有参考文件时,Claude 才会稳定复用同一套工作流,而不是每次自由发挥。
#### 核心原则 4:渐进式披露
CLAUDE.md 的职责是定义默认决策,而不是承载全部知识。对于非核心,但可能被用到的内容,正确的做法是引用,而不是复制。
```markdown
# 项目规范
## 核心
[精简的核心规范]
## 详细文档
- 数据库设计: 见 `docs/database.md`
- API 规范: 见 `docs/api-spec.md`
- 部署流程: 见 `docs/deployment.md`
```
这样做有两个好处:
- CLAUDE.md 保持轻量,启动成本低。
- 当 CLAUDE 需要进一步的详细信息时,可以按需读取文件。
### CLAUDE.md 实战演练
#### 为新项目创建 CLAUDE.md
假设你刚刚接手一个 React + Typescript 的前端项目,让我们从零配置 CLAUDE.md。
- Step 1:创建基础 CLAUDE.md
先通过 /init 命令自动初始化 CLAUDE.md 文件,或者使用下面的命令在项目根目录手动创建 CLAUDE.md 文件。
```
touch CLAUDE.md
```
然后添加如下的内容:
````markdown
# 项目:React 电商前端
## 技术栈
- React 18 + TypeScript
- Vite 构建工具
- TanStack Query (数据获取)
- Zustand (状态管理)
- Tailwind CSS (样式)
- React Router v6 (路由)
## 目录结构
```
src/
├── components/ # 可复用组件
│ ├── ui/ # 基础 UI 组件
│ └── features/ # 功能组件
├── pages/ # 页面组件
├── hooks/ # 自定义 Hooks
├── stores/ # Zustand stores
├── api/ # API 调用
├── types/ # TypeScript 类型
└── utils/ # 工具函数
```
## 编码规范
### 组件规范
- 使用函数组件 + Hooks
- Props 使用 interface 定义,命名为 `ComponentNameProps`
- 组件文件使用 PascalCase:`ProductCard.tsx`
- 每个组件一个目录,包含 index.tsx 和样式
### 状态管理
- 全局状态使用 Zustand
- 服务器状态使用 TanStack Query
- 本地状态使用 useState/useReducer
### 样式规范
- 使用 Tailwind 工具类
- 复杂样式抽取为组件
- 响应式使用 sm/md/lg/xl 断点
## 常用命令
```bash
pnpm dev # 启动开发服务器
pnpm build # 构建生产版本
pnpm test # 运行测试
pnpm lint # 代码检查
pnpm preview # 预览构建结果
```
## API 集成
- 基础 URL: `import.meta.env.VITE_API_URL`
- 使用 axios 实例,配置在 `src/api/client.ts`
- 所有 API 调用封装在 `src/api/` 目录
## Git 规范
- Commit: `type(scope): message`
- 分支: feature/_, bugfix/_, hotfix/\*
- PR 必须通过 CI 检查
````
- Step 2:创建本地记忆
```
touch CLAUDE.local.md
echo "CLAUDE.local.md" >> .gitignore
```
然后添加如下的内容:
```markdown
# 本地笔记
## 环境
- API: http://localhost:8080
- Mock: 使用 MSW
## 当前任务
- 重构购物车组件
- 截止: 本周五
```
- Step 3:添加条件规则(可选)
```
mkdir -p .claude/rules
```
然后创建 .claude/rules/testing.md,添加如下内容:
````markdown
---
paths:
- "src/**/*.test.tsx"
- "src/**/*.test.ts"
---
# 测试规范
- 使用 Vitest + React Testing Library
- 测试文件放在同目录: `Button.test.tsx`
- 优先测试用户行为,而非实现细节
```typescript
// ✅ 好
expect(screen.getByRole("button")).toBeEnabled();
// ❌ 不好
expect(component.state.isLoading).toBe(false);
```
````
#### 优化已有的 CLAUDE.md
假设你的 CLAUDE.md 已经有 500 多行,Claude 开始变慢,此时就需要给它瘦个身,做一些优化了。我们可以分三步走。
- Step 1:识别核心内容
我们可以问自己,哪些内容是每次对话都需要的?下面是对于项目整体的一个规划示例 --- 目的是使 CLAUDE.md 有一个简单而清晰的结构。
#### 企业策略级记忆设定
企业策略级记忆设定的作用是阻值范围内的指令,由 IT/DevOps 统一管理和部署组织。适合内容是公司编码标准、安全策略、合规要求以及禁止使用的库或模式。通过配置管理系统部署,确保在所有开发者机器上一致分发。
位置:
- macOS: /Library/Application Support/ClaudeCode/CLAUDE.md
- Linux: /etc/claude-code/CLAUDE.md
- Windows: C:\Program Files\ClaudeCode\CLAUDE.md
示例:
```markdown
# 公司开发策略
## 安全要求
- 禁止在代码中硬编码任何秘钥或敏感信息
- 所有 API 调用必须使用 HTTPS
- 用户输入必须经过验证和清理
## 合规要求
- 所有日志必须排除 PII(个人身份信息)
- 数据库连接必须使用加密传输
## 禁止项
- 禁止使用未经审批的第三方库
- 禁止直接访问生产数据库
```
如果你是个人或小团队,可以直接跳过企业级设定这一层,不影响任何使用。
#### 用户级内容设定
用户级内容设定承载的是你的全局偏好,如个人代码风格、沟通语言设置、通用工作习惯等。
位置:~/.claude/CLAUDE.md
示例:
```markdown
# 个人偏好
## 沟通方式
- 使用中文回复
- 代码注释使用英文
- 解释简洁直接,不要过多铺垫
## 通用代码风格
- 缩进使用 2 个空格
- 优先使用 async/await
- 变量命名使用 camelCase
- 常量命名使用 UPPER_SNAKE_CASE
## 我的常用工具
- 包管理器:pnpm
- 编辑器:VS Code
- 终端:zsh
```
用户级记忆会被项目级覆盖,如果你个人喜欢 2 个空格缩进,但项目要求 4 个空格,那就用 4 个空格。
#### 项目级团队共享规范
团队共享规范是团队共享的项目知识,应该提交到 Git。适合存放的内容包括技术栈、项目架构、编码规范、重要的设计决策和常用命令等。
位置:项目根目录的 ./CLAUDE.md
示例:
```markdown
# 项目:订单服务 API
## 技术栈
- Node.js 20 + TypeScript
- Fastify(Web 框架)
- Prisma(ORM)
- PostgreSQL + Redis
- Zod(数据验证)
## 目录结构
src/
├── routes/ # 路由定义
├── controllers/ # 请求处理
├── services/ # 业务逻辑
├── repositories/ # 数据访问
├── schemas/ # Zod schemas
└── types/ # 类型定义
## 编码规范
- TypeScript strict 模式
- 禁止使用 any,使用 unknown + 类型守卫
- 所有 API 端点必须有 Zod schema 验证
- 业务错误使用自定义 Error 类
## 常用命令
- pnpm dev - 启动开发服务器
- pnpm test - 运行测试
- pnpm prisma migrate dev - 运行数据库迁移
```
#### 本地个人工作空间
个人工作空间用于记载个人工作笔记,不提交到 Git,适合内容包括本地环境配置、个人调试技巧、当前工作备注、敏感信息(测试账号等)。
位置:项目根目录的 ./CLAUDE.local.md
示例:
```markdown
# 本地开发笔记
## 我的环境
- 本地 API:http://localhost:3000
- 测试数据库:order_service_dev
- Redis:localhost:6379
## 测试账号
- admin@test.com / test123
- user@test.com / test123
## 当前工作
- 正在重构支付模块
- 参考 PR #234 的讨论
- 周五前完成
## 调试技巧
- 订单状态机日志: LOG_LEVEL=debug pnpm dev
- 查看 Redis 缓存: redis-cli KEYS "order:\*"
```
记得把 CLAUDE.local.md 加入到 .gitignore!
```
echo "CLAUDE.local.md" >> .gitignore
```
#### 规则目录:分类组织
Rules 是按主题组织的规则文件,支持条件作用域,适合场景包括 CLAUDE.md 变得太长时、不同文件类型需要不同规范时、以及前后端分离的项目。
位置:.claude/rules/\*.md
目录结构:
```markdown
.claude/
└── rules/
├── typescript.md # TypeScript 规范
├── testing.md # 测试规范
├── api-design.md # API 设计规范
└── security.md # 安全规范
```
示例:.claude/rules/testing.md
````markdown
---
paths:
- "src/**/*.test.ts"
- "tests/**/*.ts"
---
# 测试规范
## 命名
- 单元测试: `*.test.ts`
- 集成测试: `*.integration.test.ts`
## 结构
使用 Arrange-Act-Assert 模式:
```typescript
describe("OrderService", () => {
describe("createOrder", () => {
it("should create order when stock is available", async () => {
// Arrange
const mockProduct = createMockProduct({ stock: 10 });
// Act
const order = await orderService.createOrder(mockProduct.id, 1);
// Assert
expect(order.status).toBe("created");
});
});
});
```
## 覆盖率要求
- 业务逻辑: > 80%
- 工具函数: > 90%
- 路由/控制器: 可以较低
````
此处的关键特性是 paths 字段,让这个规则只在编辑测试文件时生效,不会浪费其他场景的上下文空间。
### 编写高效的 CLAUDE.md
CLAUDE.md 写得好不好,直接决定了 Claude 是靠谱同事,还是每次都要重新培训的实习生。
下面来讨论 CLAUDE.md 编写需要遵循的核心原则,了解怎么写,才值得每次都被加载到上下文中。
#### 核心原则 1:Less is More
CLAUDE.md 的每一行,都会在每一次对话开始时被自动注入到上下文中。这意味着一件事:冗余不是无害的,是持续消耗的。所以保持精简不是建议,而是必须。
#### 核心原则 2:具体优于泛泛
先来看一个常见的,但几乎没有任何效果的写法:
```markdown
# 项目规范
## 代码质量
- 请写出高质量的代码。
- 代码应该是可读的。
- 使用有意义的变量名。
- 保持代码整洁。
- 遵循最佳实践。
```
这些内容没有一句是错的,但问题在于 --- Claude 本来就知道这些。它们不会改变 Claude 的任何决策,只会白白占用上下文空间。这些内容对人类尚且含糊,对模型来说,更是几乎等于什么都没说。
真正有价值的 CLAUDE.md,应该是这样:
````markdown
# 项目规范
## TypeScript
- 使用 `interface` 定义对象结构,`type` 用于联合类型
- 禁止 `any`,使用 `unknown` + 类型守卫
- 函数参数 > 3 个时,使用对象参数
## 错误处理
```typescript
// 业务错误
throw new BusinessError("ORDER_NOT_FOUND", "订单不存在");
// 验证错误(Zod 自动抛出)
const data = orderSchema.parse(input);
// controller 中不要 try-catch
// 由全局错误中间件统一处理
```
````
后者不是模糊要求 "要高质量",而是给出了如何做才算高质量;不是 "注意错误处理",而是给出了具体的错误模型;不是 "抽象描述",而是给出了可直接模仿的代码形态。
#### 核心原则 3:WHY/WHAT/HOW
一份真正 "能用" 的 CLAUDE.md,通常都在回答三个问题,不是一次性回答,而是在关键地方给出明确指引。
- WHY - 为什么要这样做?
```markdown
## 为什么使用 Zod?
- TypeScript 只有编译时类型检查
- API 输入需要运行时验证
- Zod 可以同时生成 TS 类型和验证逻辑
- 错误信息自动生成,对用户友好
```
这一部分的作用不是让 Claude “记住一个库”,而是让它理解背后的决策逻辑。当 Claude 明白了为什么,它在面对相似但不完全相同的场景时,才更有可能做出一致的判断。
- WHAT - 具体要做什么,不要做什么?
```markdown
## 数据库操作规范
- 所有查询通过 Prisma ORM
- 复杂查询封装在 `src/repositories/`
- 禁止在 controller/service 中直接写 SQL
- 事务使用 `prisma.$transaction()`
```
这一部分的重点是边界。什么是允许的,什么是禁止的,决策应该发生在哪一层?对于 Claude 来说,这比 "最佳实践" 四个字重要得多。
- HOW - 按什么步骤去做?
```markdown
## 创建新 API 端点
1. 在 `src/schemas/` 创建请求/响应 Zod schema
2. 在 `src/routes/` 添加路由定义
3. 在 `src/controllers/` 实现请求处理
4. 在 `src/services/` 实现业务逻辑
5. 在 `tests/` 添加测试用例
示例参考: `src/routes/orders.ts`
```
当步骤清晰、路径明确、还有参考文件时,Claude 才会稳定复用同一套工作流,而不是每次自由发挥。
#### 核心原则 4:渐进式披露
CLAUDE.md 的职责是定义默认决策,而不是承载全部知识。对于非核心,但可能被用到的内容,正确的做法是引用,而不是复制。
```markdown
# 项目规范
## 核心
[精简的核心规范]
## 详细文档
- 数据库设计: 见 `docs/database.md`
- API 规范: 见 `docs/api-spec.md`
- 部署流程: 见 `docs/deployment.md`
```
这样做有两个好处:
- CLAUDE.md 保持轻量,启动成本低。
- 当 CLAUDE 需要进一步的详细信息时,可以按需读取文件。
### CLAUDE.md 实战演练
#### 为新项目创建 CLAUDE.md
假设你刚刚接手一个 React + Typescript 的前端项目,让我们从零配置 CLAUDE.md。
- Step 1:创建基础 CLAUDE.md
先通过 /init 命令自动初始化 CLAUDE.md 文件,或者使用下面的命令在项目根目录手动创建 CLAUDE.md 文件。
```
touch CLAUDE.md
```
然后添加如下的内容:
````markdown
# 项目:React 电商前端
## 技术栈
- React 18 + TypeScript
- Vite 构建工具
- TanStack Query (数据获取)
- Zustand (状态管理)
- Tailwind CSS (样式)
- React Router v6 (路由)
## 目录结构
```
src/
├── components/ # 可复用组件
│ ├── ui/ # 基础 UI 组件
│ └── features/ # 功能组件
├── pages/ # 页面组件
├── hooks/ # 自定义 Hooks
├── stores/ # Zustand stores
├── api/ # API 调用
├── types/ # TypeScript 类型
└── utils/ # 工具函数
```
## 编码规范
### 组件规范
- 使用函数组件 + Hooks
- Props 使用 interface 定义,命名为 `ComponentNameProps`
- 组件文件使用 PascalCase:`ProductCard.tsx`
- 每个组件一个目录,包含 index.tsx 和样式
### 状态管理
- 全局状态使用 Zustand
- 服务器状态使用 TanStack Query
- 本地状态使用 useState/useReducer
### 样式规范
- 使用 Tailwind 工具类
- 复杂样式抽取为组件
- 响应式使用 sm/md/lg/xl 断点
## 常用命令
```bash
pnpm dev # 启动开发服务器
pnpm build # 构建生产版本
pnpm test # 运行测试
pnpm lint # 代码检查
pnpm preview # 预览构建结果
```
## API 集成
- 基础 URL: `import.meta.env.VITE_API_URL`
- 使用 axios 实例,配置在 `src/api/client.ts`
- 所有 API 调用封装在 `src/api/` 目录
## Git 规范
- Commit: `type(scope): message`
- 分支: feature/_, bugfix/_, hotfix/\*
- PR 必须通过 CI 检查
````
- Step 2:创建本地记忆
```
touch CLAUDE.local.md
echo "CLAUDE.local.md" >> .gitignore
```
然后添加如下的内容:
```markdown
# 本地笔记
## 环境
- API: http://localhost:8080
- Mock: 使用 MSW
## 当前任务
- 重构购物车组件
- 截止: 本周五
```
- Step 3:添加条件规则(可选)
```
mkdir -p .claude/rules
```
然后创建 .claude/rules/testing.md,添加如下内容:
````markdown
---
paths:
- "src/**/*.test.tsx"
- "src/**/*.test.ts"
---
# 测试规范
- 使用 Vitest + React Testing Library
- 测试文件放在同目录: `Button.test.tsx`
- 优先测试用户行为,而非实现细节
```typescript
// ✅ 好
expect(screen.getByRole("button")).toBeEnabled();
// ❌ 不好
expect(component.state.isLoading).toBe(false);
```
````
#### 优化已有的 CLAUDE.md
假设你的 CLAUDE.md 已经有 500 多行,Claude 开始变慢,此时就需要给它瘦个身,做一些优化了。我们可以分三步走。
- Step 1:识别核心内容
我们可以问自己,哪些内容是每次对话都需要的?下面是对于项目整体的一个规划示例 --- 目的是使 CLAUDE.md 有一个简单而清晰的结构。
 - Step 2:拆分成独立文件
详细的 API 文档、数据库表结构和部署流程虽然重要,但是完全没有必要每次都读入 Claude,可以移动到单独文件,精简原来的 CLAUDE.md。
```markdown
## 核心规范
[精简内容]
## 详细参考
- API 端点清单: @docs/api.md
- 数据库 Schema: @prisma/schema.prisma
- 部署配置: @docs/deploy.md
```
- Step 3:使用条件规则
可以考虑进一步把测试规范、前端规范、后端规范拆分到 .claude/rules/,并设置 paths 条件。
#### 记忆管理命令
要查看当前记忆,在 Claude Code 中输入:
```
/memory
```
就会显示当前加载的所有记忆内容和来源。
编辑记忆的命令参数如下:
```
/memory edit # 编辑项目级 CLAUDE.md
/memory edit user # 编辑用户级记忆
/memory edit local # 编辑本地级记忆
```
你也可以通过自然语言指令,让 Claude 帮你更新记忆!
```
你:请记住,我们项目使用 pnpm 而不是 npm
Claude:好的,我可以将这个信息添加到项目的 CLAUDE.md 中。
要我现在更新吗?
```
(灵活吧?聪明吧?)
- Step 2:拆分成独立文件
详细的 API 文档、数据库表结构和部署流程虽然重要,但是完全没有必要每次都读入 Claude,可以移动到单独文件,精简原来的 CLAUDE.md。
```markdown
## 核心规范
[精简内容]
## 详细参考
- API 端点清单: @docs/api.md
- 数据库 Schema: @prisma/schema.prisma
- 部署配置: @docs/deploy.md
```
- Step 3:使用条件规则
可以考虑进一步把测试规范、前端规范、后端规范拆分到 .claude/rules/,并设置 paths 条件。
#### 记忆管理命令
要查看当前记忆,在 Claude Code 中输入:
```
/memory
```
就会显示当前加载的所有记忆内容和来源。
编辑记忆的命令参数如下:
```
/memory edit # 编辑项目级 CLAUDE.md
/memory edit user # 编辑用户级记忆
/memory edit local # 编辑本地级记忆
```
你也可以通过自然语言指令,让 Claude 帮你更新记忆!
```
你:请记住,我们项目使用 pnpm 而不是 npm
Claude:好的,我可以将这个信息添加到项目的 CLAUDE.md 中。
要我现在更新吗?
```
(灵活吧?聪明吧?)