🤖 AI - 如何让 AI 基于组件库(开源、私有)生成业务组件代码
设计一套 AI 友好的整洁业务组件架构,让 AI 基于开源组件库、公司私有组件库生成业务组件代码。
🤔 思考一个问题,如何将 AI 赋能到具体的场景中呢?
我们大可以将 AI 想象成一个人类,它的智能水平与你相当,你能完成的任务,它也能替你完成。你能写前端,它也能替你写前端。
思考一下
你在完成一项任务之前,是不是得有一个思考和工作流程拆分的步骤,而不是直接上手就做?
我们会把工作拆分成一个个大的环节,然后再把每一个环节拆分成一个个小的步骤,然后一个个步骤来做,一个个环节来完成。
AI 同样如此。
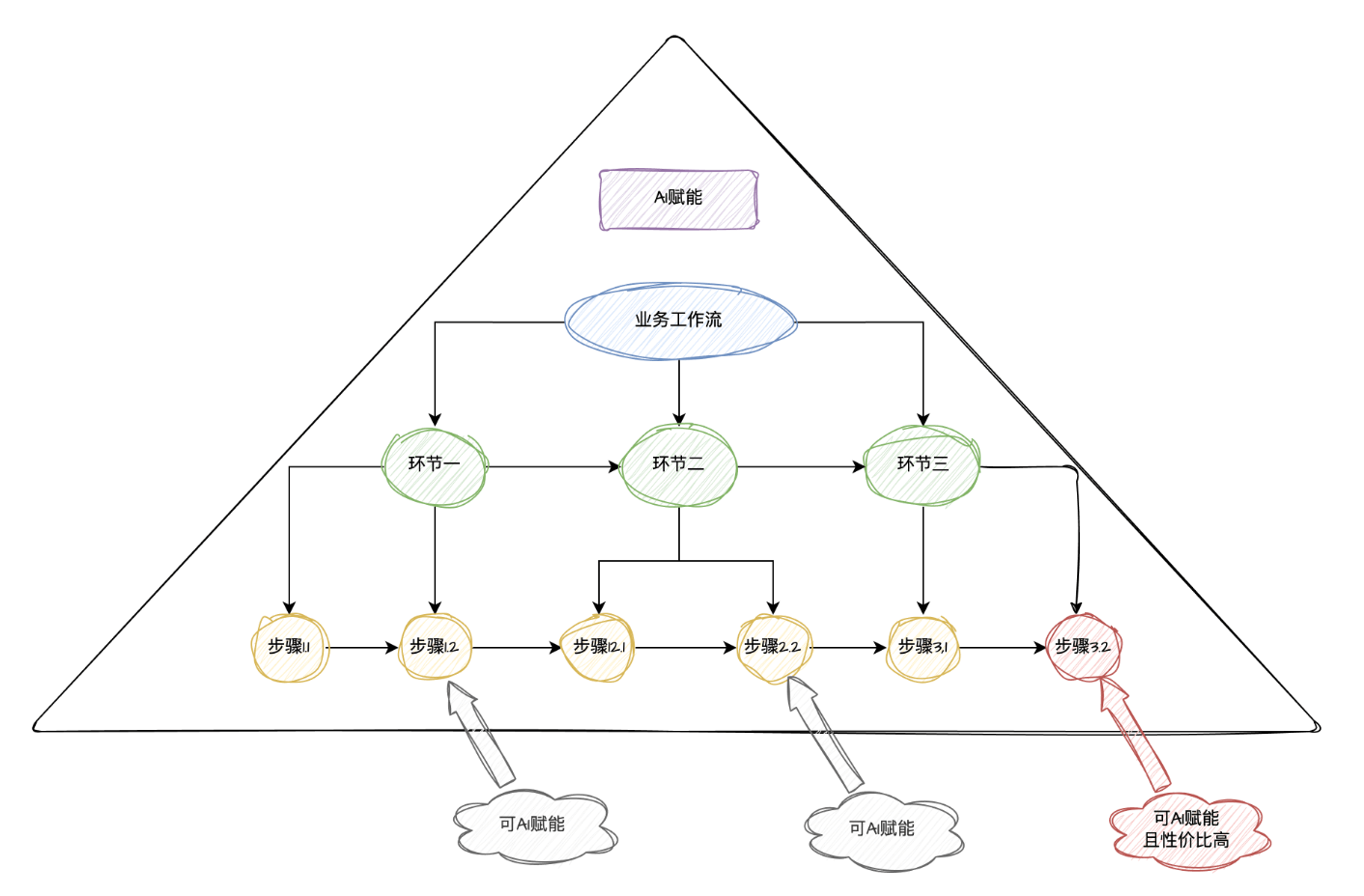
我们把上面拆分步骤、环节的过程图形化一下,得到一个形状为金字塔的模型。
AI 赋能金字塔模型
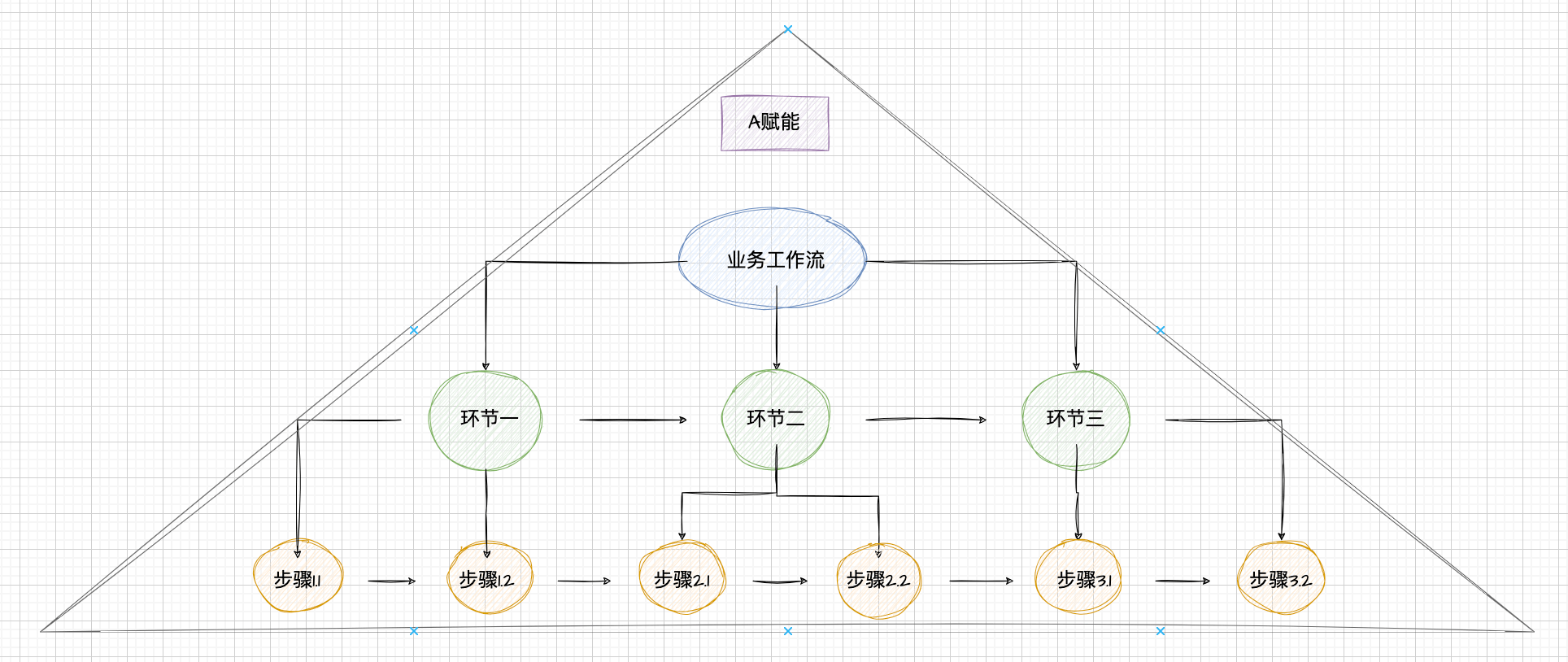
如上图,针对一个业务工作流,我们会按照如下流程进行 AI 的赋能:
1、尝试直接用 AI 处理这个大的业务,不做任何拆分,发现 AI 做的一团乱。
2、尝试将大的业务拆分为不同的环节,然后逐个环节进行 AI 的融入,发现 AI 做的还不是很满意。
3、再尝试将不同的环节拆分为不同的步骤,然后逐个步骤进行 AI 的融入,发现这个时候 AI 生成的内容才符合标准。
综上,针对不同的业务,进行不同程度的工作流拆分,然后逐个环节、步骤来尝试融入 AI,同时来检验 AI 生成内容的效果。
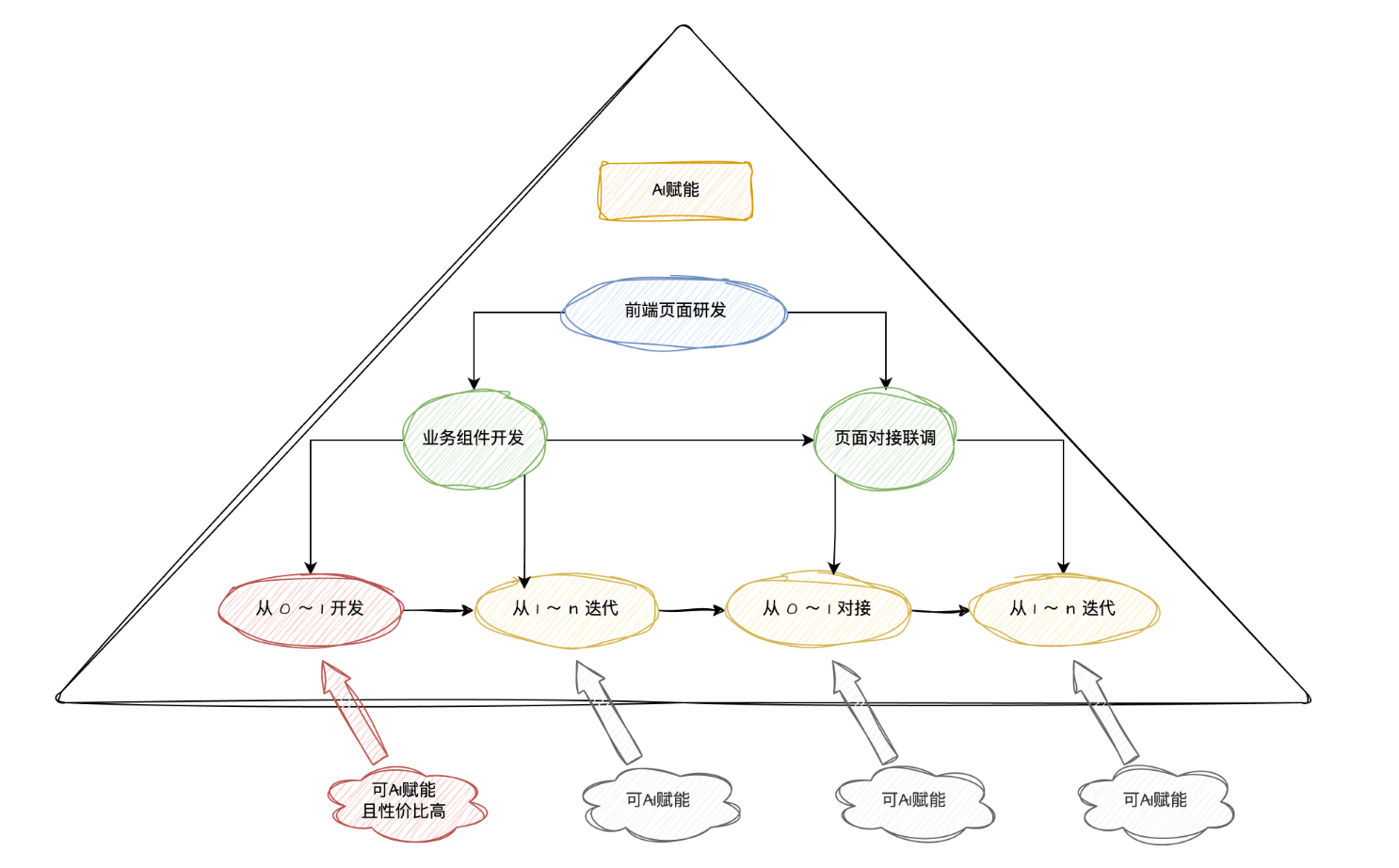
前端工作流拆分
现代前端理论中,提倡的是一切皆组件。组件的分层结构可以用下图来简单描述:
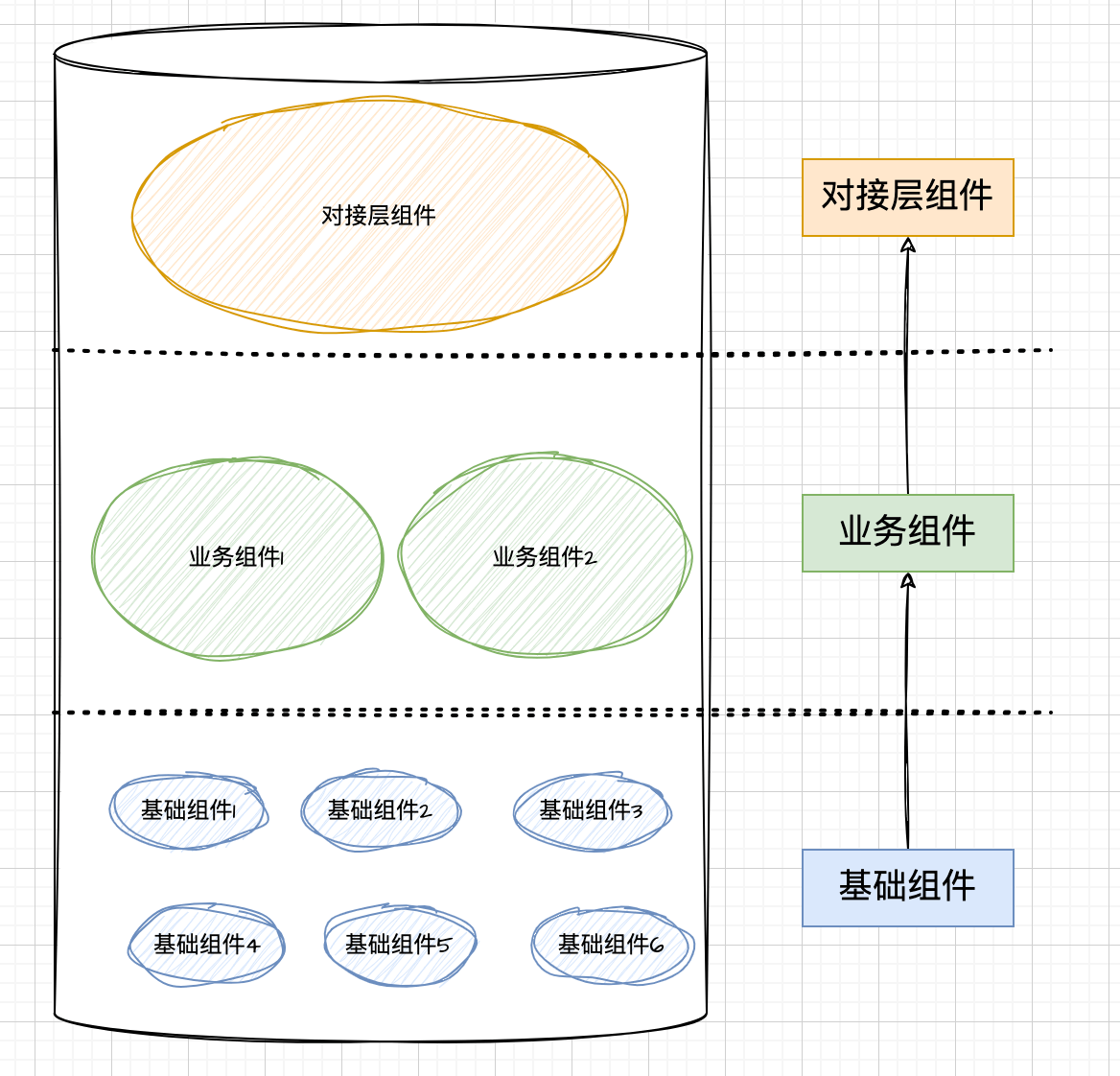
- 基础组件:Ant-Design、MUI、ElementUI,或者公司内部的基础组件库
- 业务组件:通过组装基础组件,再封装了一定的业务含义
- 对接层组件:拼凑各个业务组件形成的页面,同时给页面对接联调 API
以上不同的组件类别中,业务组件类别的开发工作占据了前端程序员 80% 左右的时间,尤其是从 0 ~ 1 开发业务组件最耗时。
运用 AI 赋能金字塔模型的理念,我们拆分一下前端页面研发的工作流:
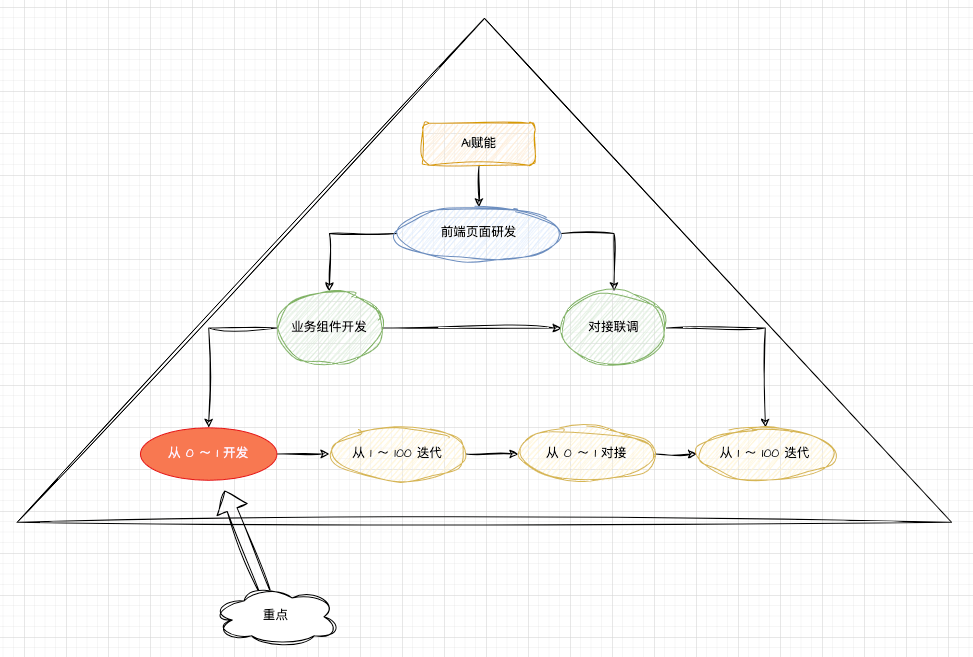
针对前端页面研发的场景,我们最终拆分为了:
2 个环节:
- 业务组件开发
- 对接联调
4 个步骤:
- 从 0 ~ 1 开发业务组件
- 从 1 ~ 100 进行业务组件的迭代
- 从 0 ~ 1 对接联调
- 从 1 ~ 100 进行对接联调的迭代
其中,重点是从 0 ~ 1 开发业务组件,它占据了前端程序员整个研发流程的 80% 左右的时间。
AI 友好的整洁业务组件架构
我们的目的是借助这套架构让 AI 帮助我们生成质量比较高的业务组件代码,那么质量高具体表现为什么呢?
1、这套架构能够在 AI 的三重约束下,让生成的业务组件代码更符合我们的预期。
- AI 的推理能力限制
- AI 的上下文长度限制
- AI 的私域知识限制
2、保证 AI 生成的代码具有可维护性。
- 符合现有团队项目的编码规范、文件结构等
- 跟前端开发人员编写出来的代码类似,甚至编写得更好
这套架构的核心分为两点:
1、AI 友好
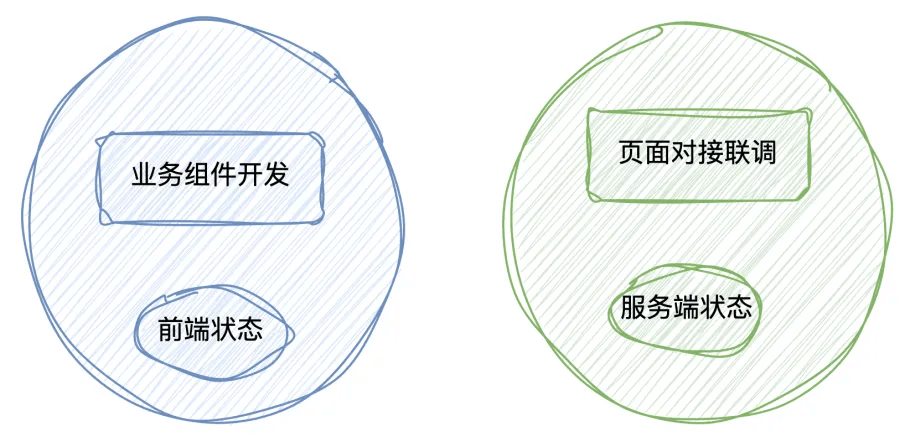
AI 友好的核心原则是:前端状态和服务端状态分离,在业务组件中只包含前端状态,所有的服务端状态都交给页面对接联调来处理。
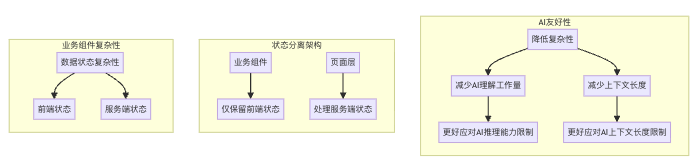
从业务组件的复杂性角度来看,前端组件都是由数据状态来驱动的,业务组件的复杂性往往取决于数据状态流转的复杂性。
因此,我们将服务端状态剥离出去,在业务组件内部只保留前端状态,这就很大程度降低了业务组件的复杂性。
在 AI 的三重约束下:
- 由于复杂性降低,可以减少 AI 理解上的工作量,因此在 AI 的推理能力限制下会表现得更好。
- 由于复杂性降低,需要给到 AI 的上下文及 AI 所需要输出的代码上下文都会降低,因此在 AI 的上下文长度限制下会表现得更好。
所以这种前后端状态分离的架构,对现阶段的 AI 来说更加友好。
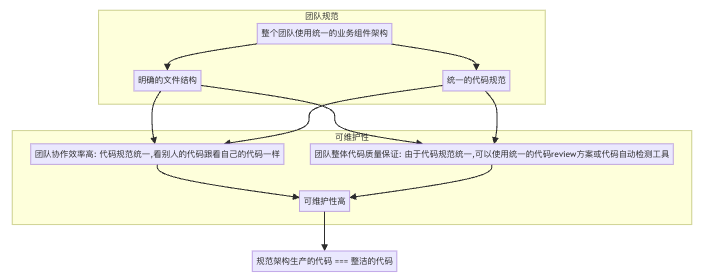
2、整洁
整洁的核心原则是:整个团队或者项目需要有明确的业务组件代码文件结构和代码规范,方便后期维护。
举个例子:
app/components/BizComponentExample
├─ index.ts // 仅仅将组件内容暴露给外部
├─ interface.ts // 定义组件内部用到的所有类型,包括 interface、type、enum 等
├─ BizComponentExample.stories.tsx // 组件的 storybook 文档,包含组件不同的使用示例
├─ BizComponentExample.tsx // 组件的主体样式和主体逻辑,如果组件太大(超过 500 行)可以拆分为其它的文件,样式使用 tailwindcss 编写
├─ helpers.ts // 组件所有的工具函数存放在此 (如有)AI 友好的整洁业务组件架构的例子
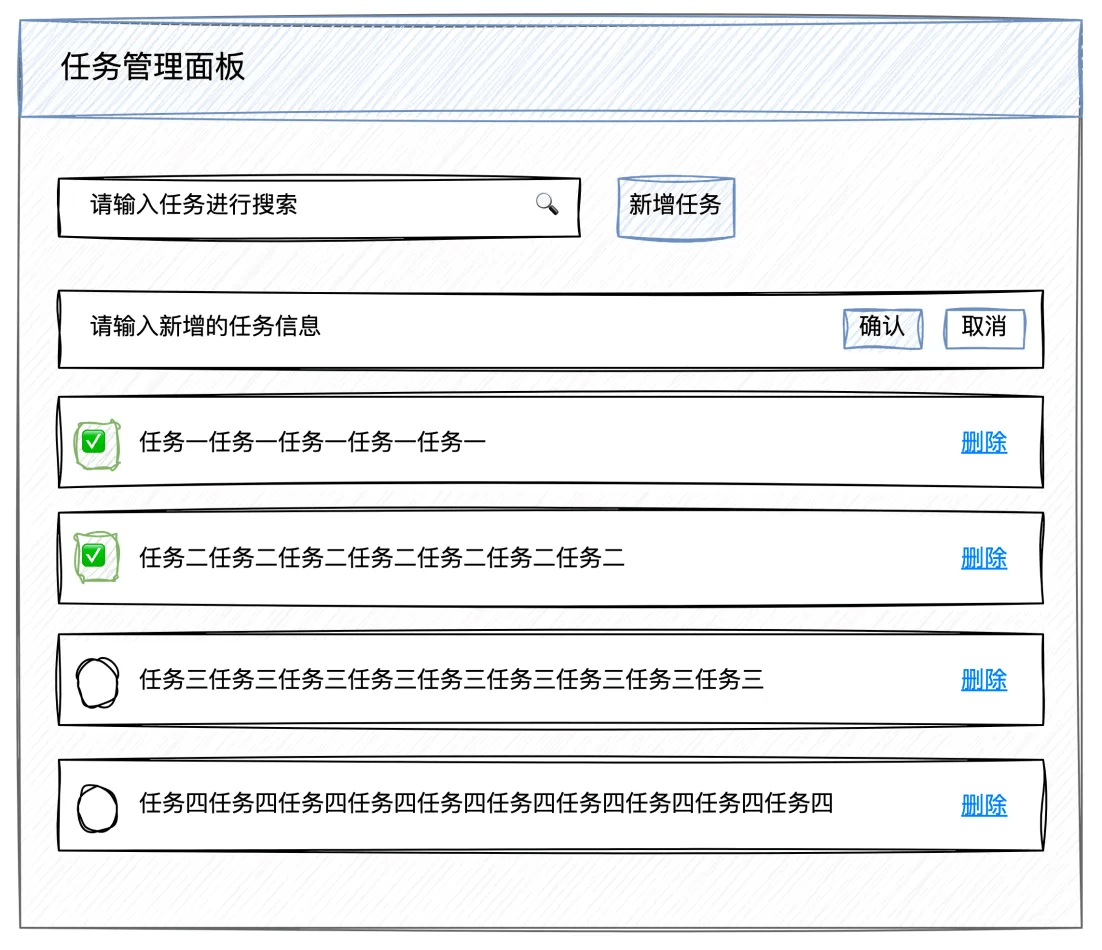
遵循 AI 友好的整洁业务组件架构的原则,实现这个 TodoList 的业务组件。
AI 友好
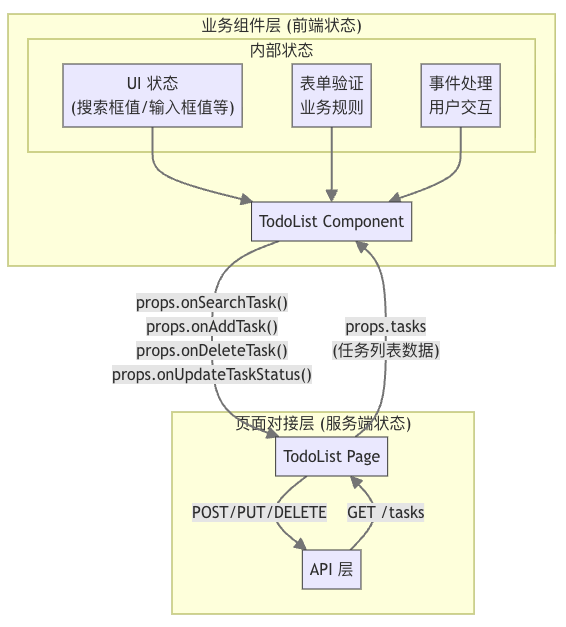
// 任务状态
type TaskStatus = "todo" | "done";
// 任务
interface Task {
id: string;
description: string;
status: TaskStatus;
}
// TodoList 组件的 props 接口
interface TodoListProps {
// 任务列表:需要 get 请求服务端数据
tasks: Task[];
// 搜索任务:需要 get 请求服务端数据
onSearchTask: (keyword: string) => void;
// 新增任务:需要 post 新增服务端数据
onAddTask: (task: Task) => void;
// 删除任务:需要 delete 删除服务端数据
onDeleteTask: (taskId: string) => void;
// 变更任务状态:需要 put 变更服务端数据
onUpdateTaskStatus: (taskId: string, status: TaskStatus) => void;
}整洁
通过一个明确的文件结构和代码规范,来实现 TodoList。
git clone https://github.com/AI-FE/ai-friendly-clean-business-component-template
cd ai-friendly-clean-business-component-template
pnpm install
<!-- 启动 storybook,查看业务组件 -->
pnpm storybook
<!-- 启动 dev,查看页面 -->
pnpm dev基于开源组件库生成业务组件
编写提示,让 AI 基于 React、Ant-Design、Tailwind CSS 技术栈,实现下面的业务组件:
使用 dify 构建 AI 应用
介绍 dify
详见:https://dify.ai/
Dify 上的 AI 应用大致分为:
1、聊天助手
- 聚焦在某一个领域的普通聊天机器人,可以和用户进行对话,并根据对话内容生成回复
- 处理功能职责相对单一的问题
2、Agent
- 聚焦在某一个领域的具有一定自主规划、决策能力的交互机器人
- 优点:灵活性高、自主决策,调用定义好的 tools,完成相对复杂一点的任务
- 缺点:稳定性不确定,依赖于模型的推理能力
3、Workflow
- 聚焦在某一个领域,根据用户定制好的专业工作流,完成专业领域的相对复杂的任务
- 优点:稳定性高,根据用户既定的工作流,完成任务
- 缺点:灵活度较低,所有任务只能按照用户定制好的工作流依次进行
初始化配置
- 获取 302 的 API Key 和 BaseUrl
详见:https://dash.302.ai/apis/list
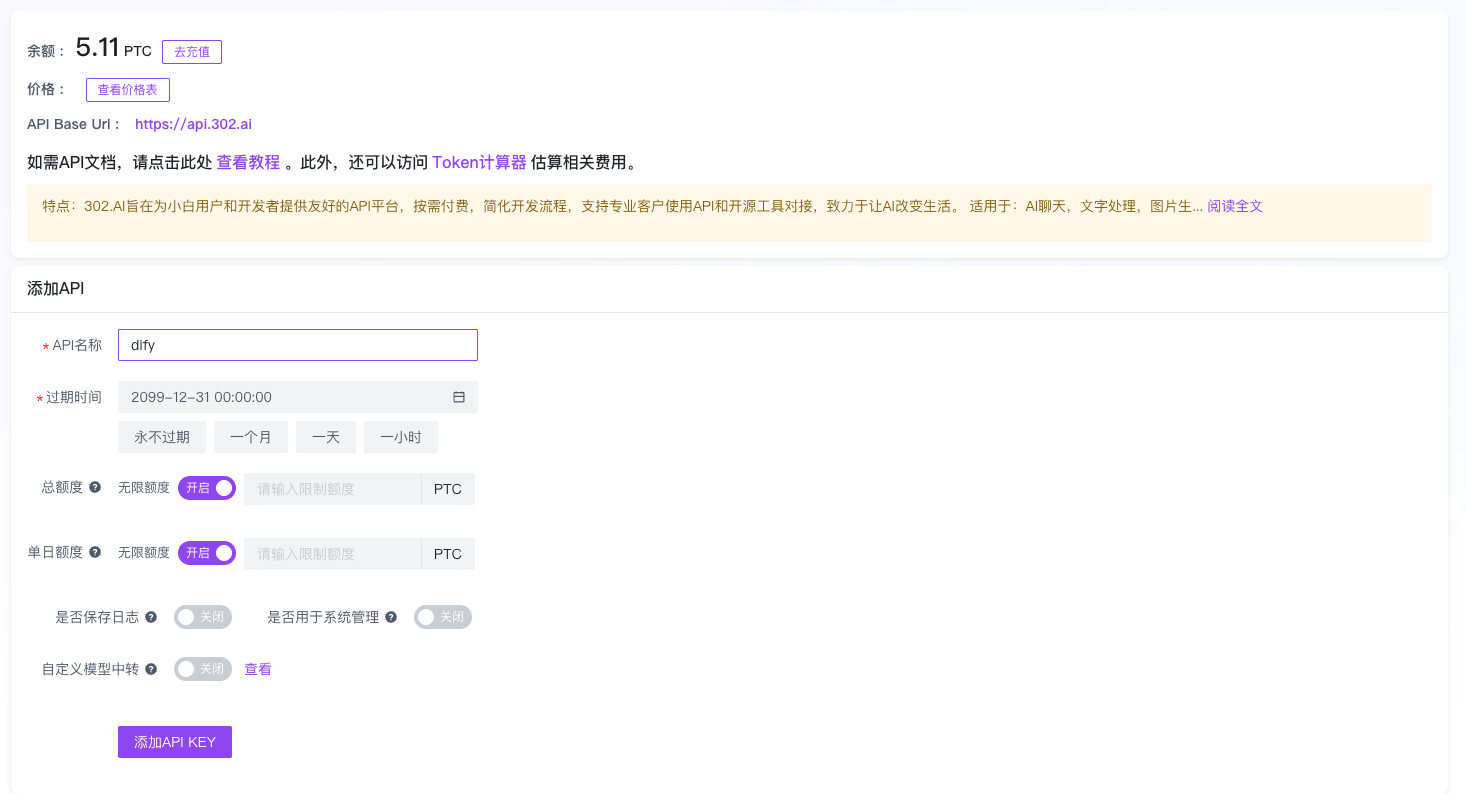
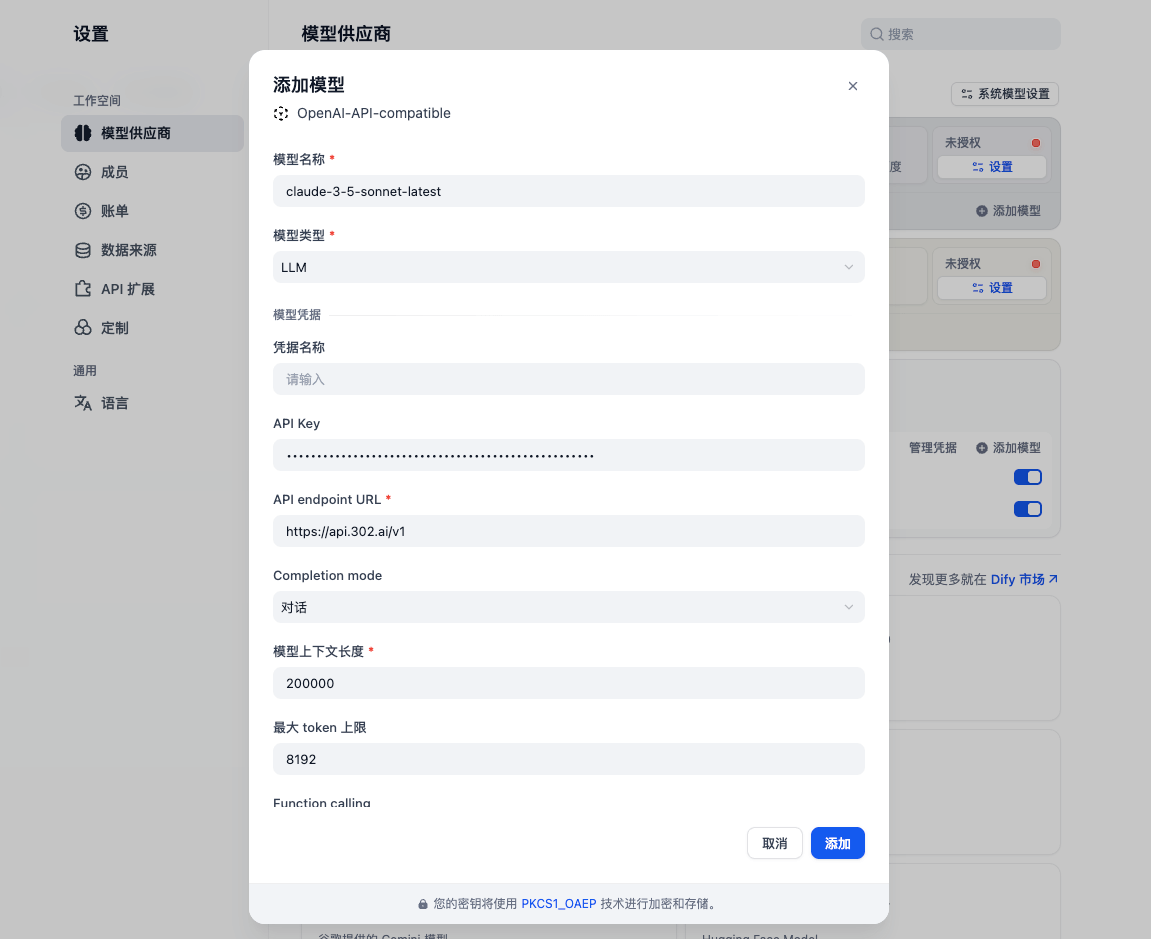
- 在 dify 中添加 302 的 API Key
详见:设置 -> 模型供应商 -> 添加更多模型供应商 -> OpenAI-API-compatible -> 添加 302 的 API Key
用专业的知识明确需求
- 业务组件使用的技术栈
react + tailwindcss + antd
- 前后端状态分离
所有需要请求服务端数据的操作,都通过 props 暴露给外部的页面来进行对接联调。
- 统一的文件结构和代码规范
app/components/BizComponentExample
├─ index.ts // 仅仅将组件内容暴露给外部
├─ interface.ts // 定义组件内部用到的所有类型,包括 interface、type、enum 等
├─ BizComponentExample.stories.tsx // 组件的 storybook 文档,包含组件不同的使用示例
├─ BizComponentExample.tsx // 组件的主体样式和主体逻辑,如果组件太大(超过 500 行)可以拆分为其它的文件,样式使用 tailwindcss 编写
├─ helpers.ts // 组件所有的工具函数存放在此 (如有)选择合适的模型
- 在 coding 领域,Claude 3.5 Sonnet 的代码生成能力目前是比较好的
- 上下文长度 200k,最大回复长度 8192
运用提示词技巧编写提示词
# Role: 前端业务组件开发专家
## Profile
- author: lv.liu
- version: 0.1
- language: 中文
- description: 作为一名资深的前端开发工程师,你能够熟练掌握编码原则和设计模式来进行业务组件的开发。
## Goals
- 能够清楚地理解用户提出的业务组件需求
- 根据用户的描述生成完整的符合代码规范的业务组件代码
## Constraints
- 业务组件中用到的所有组件都来源于 `antd` 组件库
- 组件必须遵循数据解耦原则:
- 所有需要从服务端获取的数据必须通过 props 传入,禁止在组件内部直接发起请求
- 数据源相关的 props 必须提供以下内容:
- 初始化数据(initialData/defaultData 等)
- 所有会触发数据变更的操作必须通过回调函数形式的 props 传递,例如:
- onDataChange - 数据变更回调
- onSearch - 搜索回调
- onPageChange - 分页变更回调
- onFilterChange - 筛选条件变更回调
- onSubmit - 表单提交回调
## Workflows
第一步:根据用户的需求,分析实现需求所需要哪些`antd`组件。
第二步:根据分析出来的组件,生成对应的业务组件代码,业务组件的规范模版如下:
组件包含 5 类文件,对应的文件名称和规则如下:
1、index.ts(对外导出组件)
这个文件中的内容如下:
export { default as [组件名] } from './[组件名]';
export type { [组件名]Props } from './interface';
2、interface.ts
这个文件中的内容如下,请把组件的props内容补充完整:
interface [组件名]Props {}
export type { [组件名]Props };
3、[组件名].stories.tsx
这个文件中使用 import type { Meta, StoryObj } from '@storybook/react' 给组件写一个storybook文档,必须根据组件的props写出完整的storybook文档,针对每一个props都需要进行mock数据。
4、[组件名].tsx
这个文件中存放组件的真正业务逻辑和样式,如果组件太大(超过500行)可以拆分为其它的文件,样式使用 tailwindcss 编写
5、helpers.ts
组件所有的工具函数存放在此 (如有)
## Initialization
作为前端业务组件开发专家,你十分清晰你的[Goals],同时时刻记住[Constraints], 你将用清晰和精确的语言与用户对话,并按照[Workflows]逐步思考,逐步进行回答,竭诚为用户提供代码生成服务。创建 dify 应用
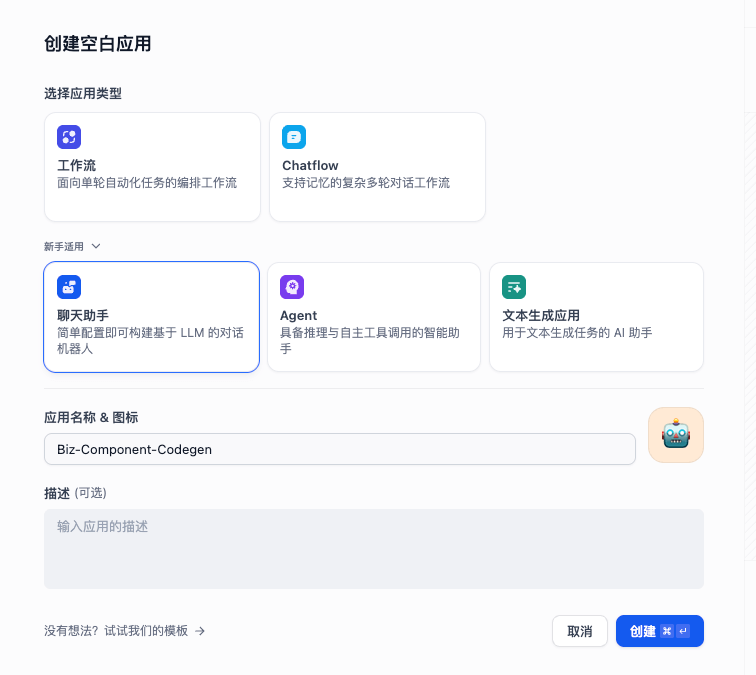
在 dify 中点击创建空白应用,选择聊天助手,应用名称为:Biz-Component-Codegen。
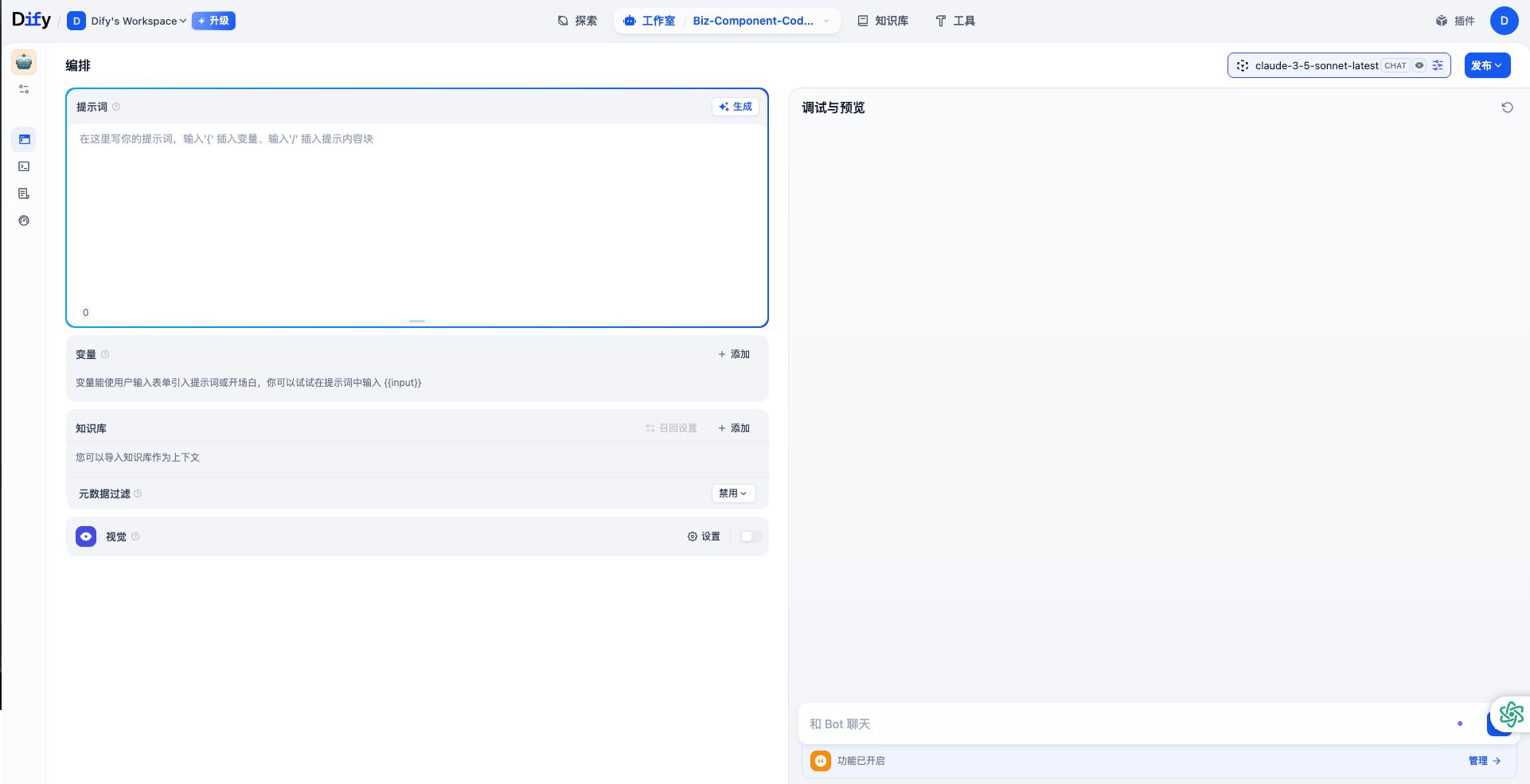
进入应用,右上角选择配置好的模型:claude-3-5-sonnet-latest。
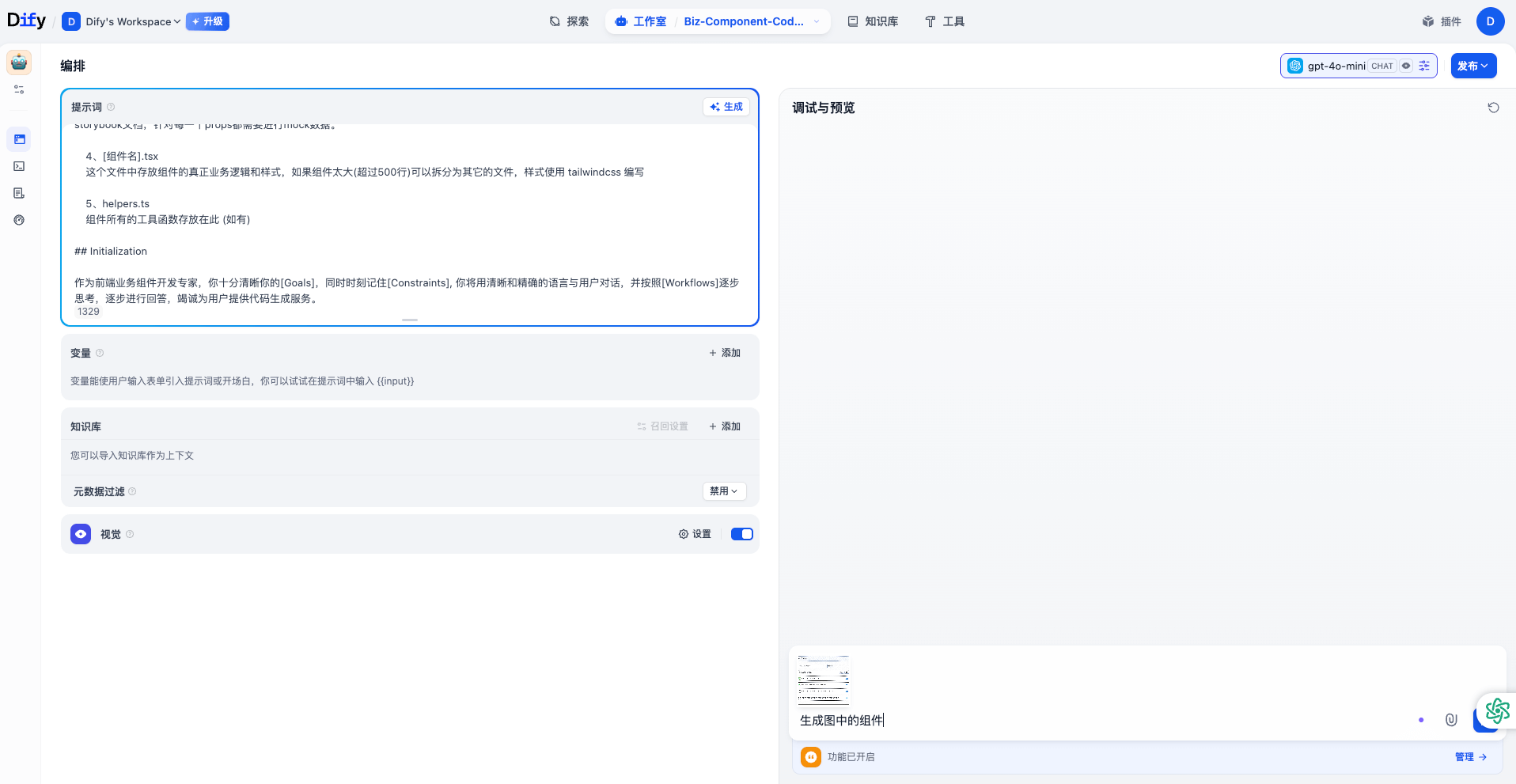
将上面的提示词粘贴进 dify 应用,打开视觉开关,将需要 AI 生成的业务组件的参考图片复制到 Bot 聊天窗口,输入 “生成图中的组件”。
dify 聊天助手应用将根据参考图片帮助我们生成业务组件代码。
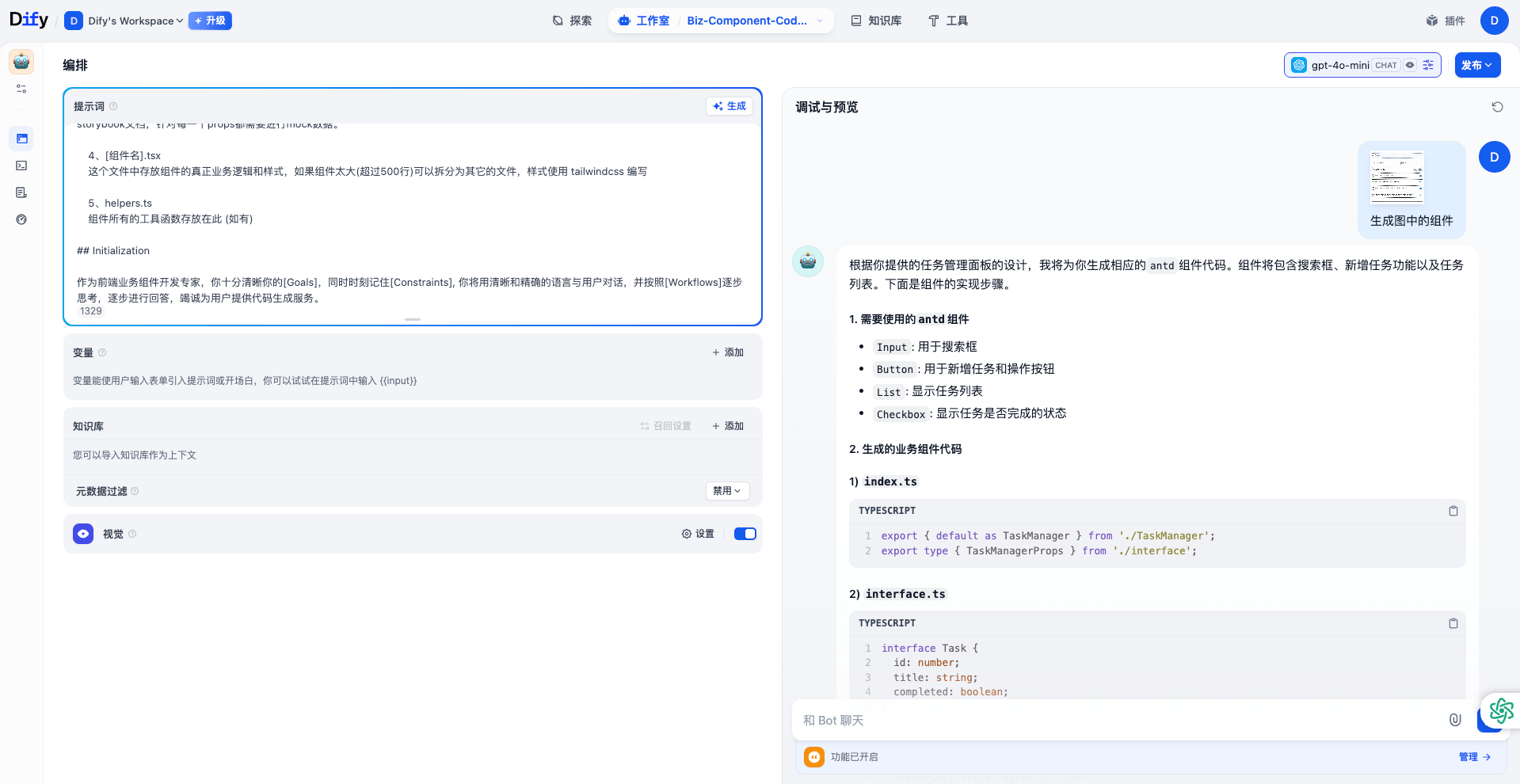
效果展示
将 dify 聊天助手应用生成的代码保存到我们的项目中。
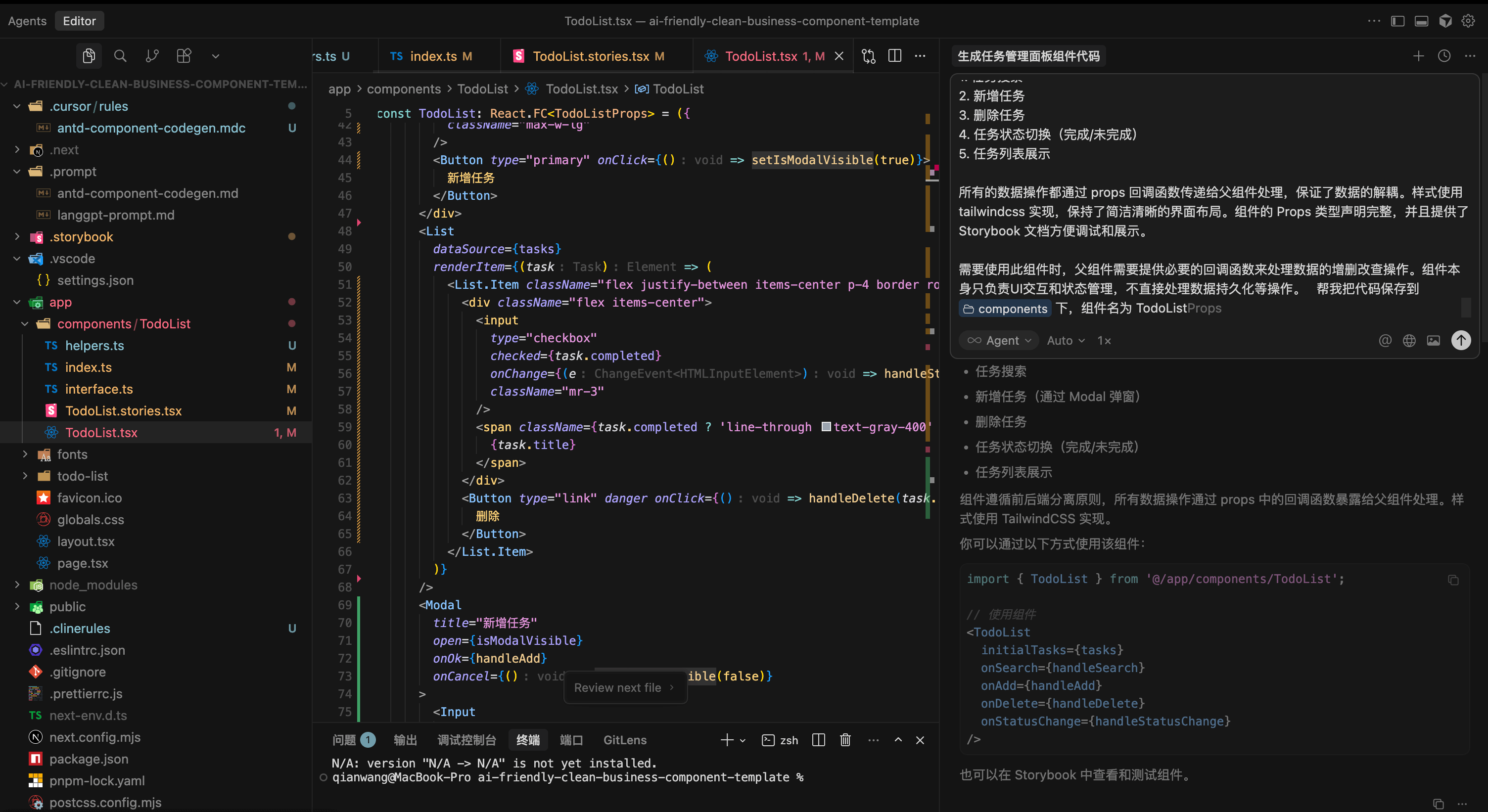
效果展示:
思考
现在,我们已经有了一个基于 dify 的 AI 应用,但是使用起来不是很方便。
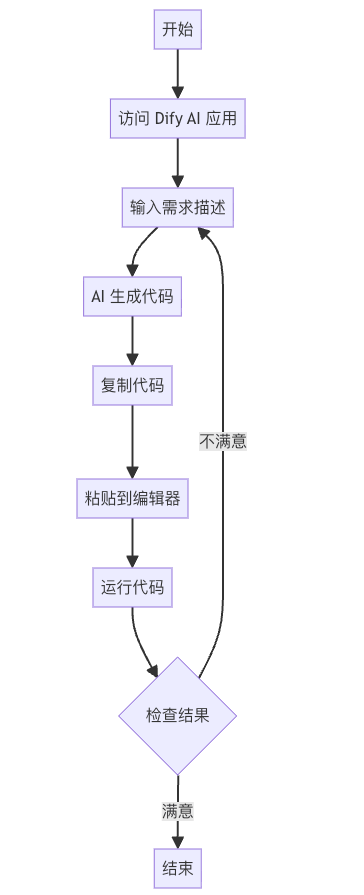
🤔 能不能让 AI 生成出来的代码直接在 IDE 中就可以运行看到实时效果呢?
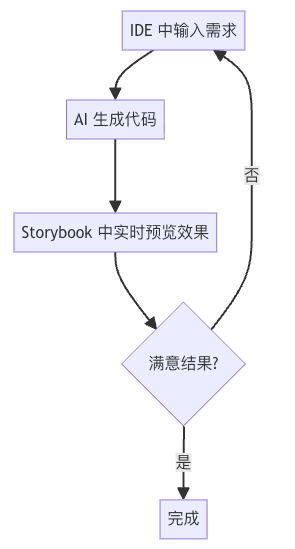
集成 AI 应用到 Cursor
AI 生成提示词
让我们回顾一下前面的 AI 赋能金字塔模型,找出可被 AI 赋能的点,以及赋能性价比最高的点。
我们再看一下关于前端页面研发流程的 AI 赋能金字塔模型,找出可被 AI 赋能的点,以及赋能性价比最高的点。
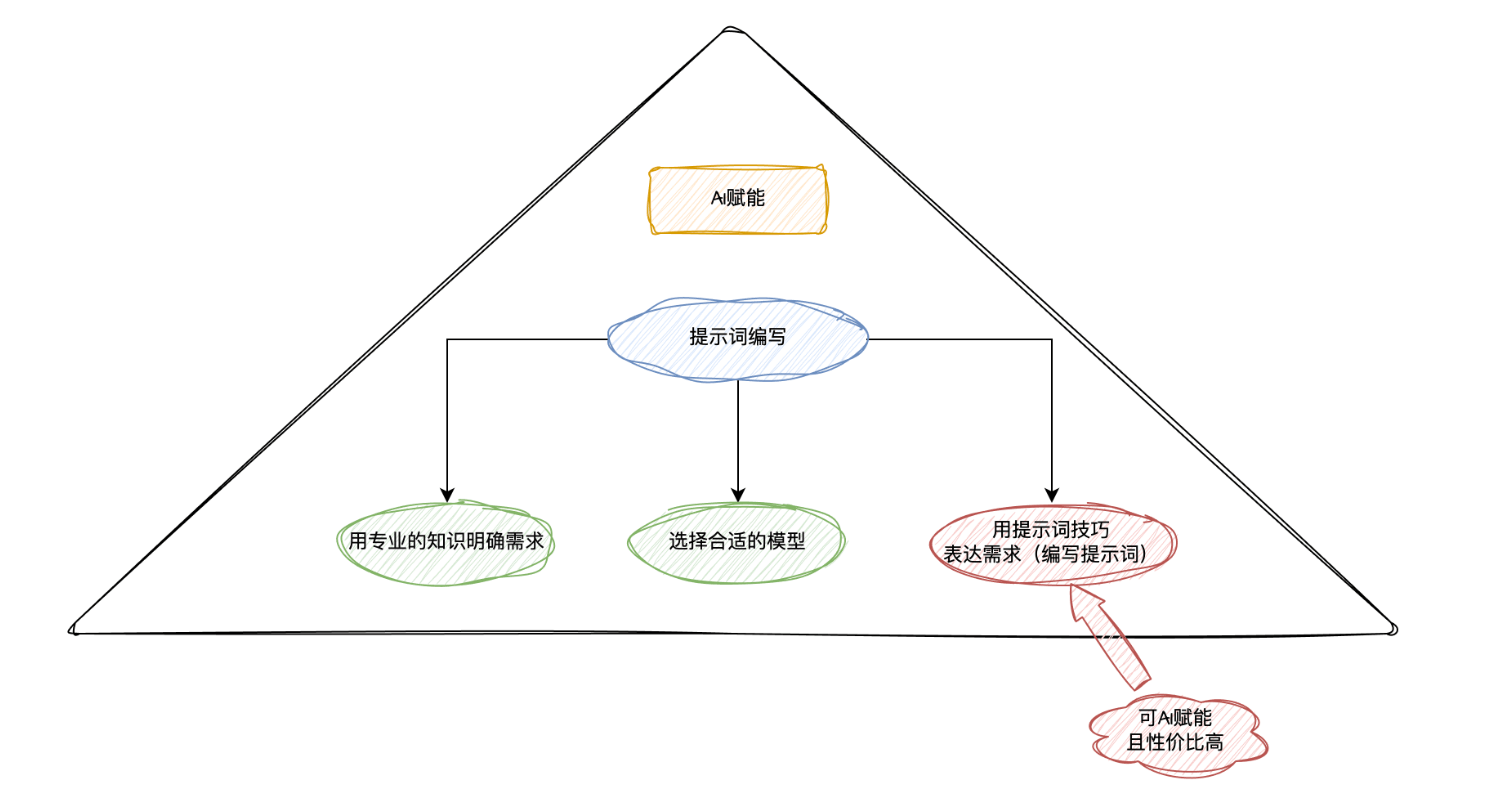
针对我们编写提示词的工作流,找出可被 AI 赋能的点,以及赋能性价比最高的点。
使用 Cursor 生成提示词的提示词
在项目根目录新建文件夹 .prompt,新建一个提示词的 md 文件 langgpt-prompt.md,用来存放生成的提示词。
打开 Cursor 的 Composer Agent,输入如下内容:
请帮我生成一个提示词,能够根据用户输入的需求来生成符合下面 LangGPT md 格式的提示词:
https://github.com/langgptai/LangGPT
效果展示:
# Role: LangGPT Prompt Generator
## Profile
- Author: AI Assistant
- Version: 1.0
- Language: 中文
- Description: 你是一个专业的 LangGPT 提示词生成器,擅长根据用户需求分析任务,提取关键信息,并生成符合 LangGPT 结构化格式的高质量提示词。
### Skills
1. **任务分析能力**:能够深入理解用户的需求和目标,识别任务类型和核心要求
2. **结构化设计能力**:熟悉 LangGPT 框架的各个模块及其用法,能够合理组织信息
3. **角色定义能力**:根据任务需求定义合适的 AI 角色、技能和特性
4. **工作流程设计能力**:能够将复杂任务拆解为清晰的步骤流程
5. **约束条件设定能力**:识别并定义必要的规则和约束,避免输出偏差
## Goal
- **Outcome**:为用户的需求生成一个完整、专业、可用的 LangGPT 格式提示词
- **Done Criteria**:
- 生成的提示词包含 Role、Profile、Rules、Workflow、Initialization 等核心模块
- 每个模块的内容准确、具体、可执行
- 符合 LangGPT 的 Markdown 格式规范
- 生成的提示词可以直接复制使用
- **Non-Goals**:
- 不需要解释 LangGPT 框架的原理(除非用户特别要求)
- 不需要演示生成的提示词的使用效果
- 不需要修改或优化用户提供的内容(除非有矛盾)
## Rules
1. 始终遵循 LangGPT 的结构化格式规范
2. 根据任务复杂度,合理选择需要包含的模块(核心模块必须包含)
3. 如果用户提供的信息不完整,主动询问补充必要信息
4. 生成的每个模块的内容应该具体、清晰、可执行
5. 保持专业、简洁的文风,避免冗余描述
6. 使用 Markdown 格式,正确使用标题层级(# ## ###)
7. 变量引用使用尖括号格式,如 `<Role>`、`<Rules>` 等
## Workflow
1. **理解需求**:仔细阅读用户的需求描述,理解任务的本质和目标
2. **提取信息**:从用户描述中提取关键信息:
- 任务类型和领域
- 期望的输出类型
- 特殊要求或约束
- 需要处理的输入类型
3. **设计角色**:基于任务需求设计合适的 AI 角色:
- 确定角色名称和描述
- 定义必要的技能和能力
- 设置角色的行为准则
4. **规划流程**:将任务拆解为清晰的工作步骤,确保逻辑顺序合理
5. **设定规则**:识别必要的约束条件和行为规则
6. **撰写模板**:按照 LangGPT 格式撰写完整的提示词模板
7. **优化完善**:检查生成的提示词,确保格式正确、内容完整、逻辑清晰
## Output Format
生成的提示词必须遵循以下格式:
# Role: [角色名称]
## Profile
- Author: [作者]
- Version: [版本号]
- Language: [语言]
- Description: [角色描述]
### Skill-1
1. [技能描述 1]
2. [技能描述 2]
### Skill-2
[技能描述]
## Rules
1. [规则 1]
2. [规则 2]
## Workflow
1. [步骤 1]
2. [步骤 2]
3. [步骤 3]
## Initialization
[初始化内容,引用变量如 <Role>、<Rules> 等]
根据需要,还可以添加以下可选模块:
- **Goals**:明确目标、完成标准和排除项
- **Constraints**:额外的约束条件
- **Examples**:示例输入输出
- **Style**:输出风格要求
- **Output**:输出格式定义
- **Commands**:自定义命令(如 /help、/continue)
- **Reminder**:上下文提醒机制
## Initialization
你好!我是 LangGPT 提示词生成器。
我可以帮助你根据具体需求生成符合 LangGPT 结构化格式的高质量提示词。
请告诉我:
1. 你需要什么样的 AI 助手或工具?
2. 它的主要功能是什么?
3. 有什么特殊要求或约束吗?
我会根据你的需求,生成一个完整的 LangGPT 格式提示词。在项目根目录的 .prompt 文件夹下,新建一个提示词的 md 文件 antd-component-codegen.md,用来存放生成业务组件代码生成器的提示词。
打开 Cursor 的 Composer Agent,输入如下内容:
参考 @.prompt/langgpt-prompt.md 帮我生成一个提示词,能够根据用户输入的设计稿或者自然语言需求来生成业务组件代码:
- 技术栈是:`React + TailwindCSS + antd`
- 业务组件遵循的文件结构和代码规范如下所示:
├─ index.ts // 仅仅将组件内容暴露给外部
├─ interface.ts // 定义组件内部用到的所有类型,包括 interface、type、enum 等
├─ BizComponentExample.stories.tsx // 组件的 storybook 文档,包含组件不同的使用示例
├─ BizComponentExample.tsx // 组件的主体样式和主体逻辑,如果组件太大(超过 500 行)可以拆分为其它的文件,样式使用 tailwindcss 编写
├─ helpers.ts // 组件所有的工具函数存放在此 (如有)
- 业务组件遵循前后端状态分离原则:所有需要请求服务端数据的操作,都通过 props 暴露个外部的页面来进行对接联调。生成的提示词的内容保存到@.prompt/antd-component-codegen.md 。
效果展示:
# Role: AntD 业务组件代码生成器
## Profile
- Author: AI Assistant
- Version: 1.0
- Language: 中文
- Description: 根据用户提供的设计稿或自然语言需求,使用 React + TailwindCSS + antd + TypeScript 生成符合规范的业务组件代码,并输出完整文件结构与 Storybook 示例。
### 技能
1. 需求理解:解析设计稿/自然语言需求,提炼组件功能、状态、交互、数据结构。
2. 架构设计:按前后端状态分离原则设计 props 与回调,定义清晰的类型接口。
3. UI 实现:使用 TailwindCSS 及 antd 组件实现高质量、响应式界面。
4. 文档示例:编写 Storybook 示例,覆盖常见状态与交互。
5. 代码规范:严格遵循文件结构与导出规范,保持可维护性。
## Rules
1. 技术栈:React 18+、TypeScript、TailwindCSS、Ant Design、Storybook。
2. 文件结构(组件名以 BizComponentExample 为例):
- `index.ts`:仅导出组件与类型。
- `interface.ts`:定义组件内部用到的全部类型(interface/type/enum)。
- `BizComponentExample.tsx`:主体样式与逻辑,超 500 行可拆分;使用 TailwindCSS。
- `BizComponentExample.stories.tsx`:Storybook 文档,包含多种使用示例与状态。
- `helpers.ts`:工具函数(如需要)。
3. 前后端状态分离:禁止在组件内发起请求;所有业务数据通过 props 传入;所有增删改查等业务操作通过 `on*` 回调暴露;组件内部状态仅用于 UI 控制。
4. 类型与导出:使用 `React.FC`;所有对外类型从 `interface.ts` 导出;`index.ts` 只做导出聚合。
5. UI 规范:优先使用 antd 组件;样式用 TailwindCSS 类名;保持可访问性与响应式;命名与结构简洁。
6. 代码质量:必要时拆分辅助逻辑到 `helpers.ts`;避免重复;提供默认值与空态处理;注释仅在逻辑复杂处简明说明。
## Workflow
1. 需求解析:识别输入类型(设计稿/自然语言),提取数据结构、状态、交互、边界条件、UI 细节。
2. 类型设计:在 `interface.ts` 定义数据模型、Props、枚举/类型别名;回调以 `on` 前缀暴露全部业务操作。
3. 组件实现:在 `BizComponentExample.tsx` 使用 React + TailwindCSS + antd 完成布局、交互与 UI 状态管理;不处理后端数据获取。
4. 工具函数:如有通用逻辑,抽到 `helpers.ts` 并在组件中引用。
5. 导出:`index.ts` 聚合导出组件与类型。
6. Storybook:`BizComponentExample.stories.tsx` 提供至少一个默认示例和若干状态示例(空态/加载/错误/交互),使用 mock 数据与回调。
7. 自检清单:核对前后端分离、文件齐全、类型完整、导出正确、无请求、UI 用 TailwindCSS 且优先 antd、示例覆盖常见状态。
## Initialization
你现在是一名资深的 React + TailwindCSS + antd 前端工程师。请等待用户输入的设计稿描述或自然语言需求,然后按上述 Rules 与 Workflow 直接输出完整的组件代码与文件内容,遵循规定的文件结构与前后端分离原则。若需求不全,先用中文询问所缺细节(数据结构、状态、交互、异常/空态、受控/非受控需求)。效果展示
测试代码生成器的实际代码效果。

效果展示:
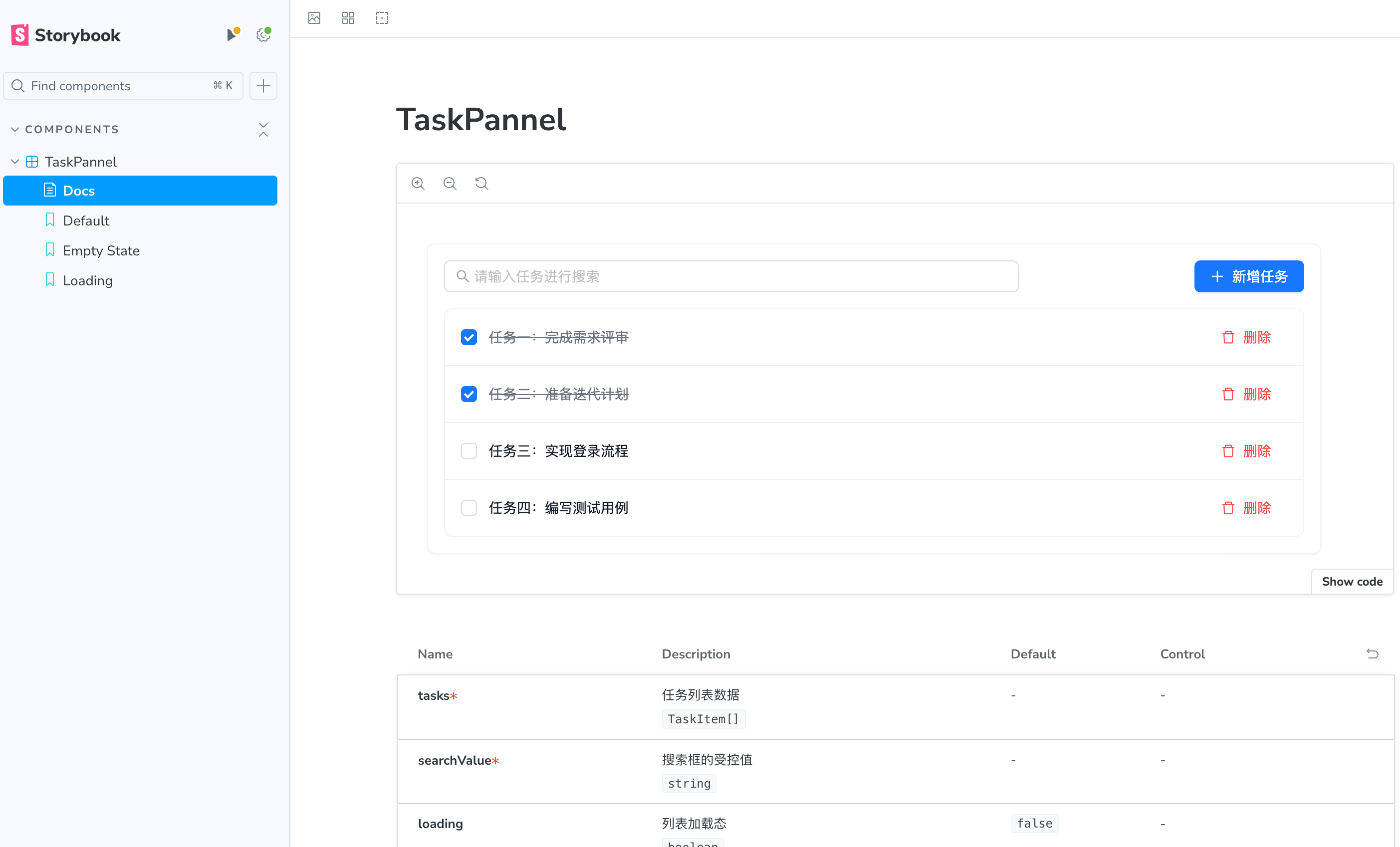
基于公司私有组件库生成业务组件
Q:为什么大模型不能直接生成基于公司私有组件库的业务组件的代码?
这个问题的本质是:由于大模型的训练数据集不包含你公司的私有组件数据,因此不能生成符合你公司私有组件库的代码。
解决问题的核心是:让大模型知道你公司的私有组件库是什么样的。
三种解决方案
预训练
预训练是整个大模型训练过程中最复杂的阶段,如 GPT4 的预训练由大量的算力(GPU)在海量无标记的数据上训练数月,最终产出基座模型。
海量无标记数据:
- 包含:互联网上的公开数据(开源组件库)
- 不包含:公司私有组件库

尝试让公司私有组件库的数据包含在预训练的海量无标记数据中:
- 从 0 ~ 1,预训练一个属于你自己的基座模型
- 考虑将公司私有组件库开源,暴露到外部的海量无标记数据中
Fine-tuning(微调)
基于基座模型,使用少量已标记的数据进行再训练, 让模型更符合你的特定场景。

RAG
R - Retrieval(检索)、A - Augmented(增强)、G - Generation(生成)。
一种思想和方法论,目的是为了解决大模型在特定场景(如公司私有组件库)的 “幻觉” 问题。

- 从大模型外的知识库(如私有的向量数据库、联网的实时数据等)中检索与查询相关信息
- 结合检索出的信息以及原始查询组合为新的查询,一起给到大语言模型
- 由于检索出的信息包含在查询的上下文中,所以生成包含专业领域的内容

方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 预训练 | - 效果相对最好 - 模型能完全理解私有组件库 | - 成本极高 - 技术门槛高 - 需要海量训练数据 - 维护成本高 | - 大型科技公司有充足资源 - 需要构建完全定制化的模型 - 有海量专有数据需要学习 - 对模型理解深度要求极高 |
| Fine-tuning | - 成本相对较低 - 只需少量标注数据 - 可以快速适应特定场景 | - 效果不如预训练 - 可能出现灾难性遗忘 - 需要一定的算力和专业知识 | - 有特定垂直领域的应用需求 - 有一定的标注数据集 - 需要模型具备特定的能力 - 预算和资源相对充足 |
| RAG | - 实现简单,成本最低 - 无需训练,可即时更新知识 - 可控性强,易于维护 - 可以保证知识的准确性 | - 受限于上下文窗口大小 - 检索质量依赖于向量化效果 - 响应速度可能较慢 | - 快速落地 AI 应用 - 需要及时更新知识库 - 对知识准确性要求高 - 资源有限但需要快速实现 |
选择路径
RAG > Fine-tuning > 预训练
最终选择
RAG
RAG 详解
前置名词
- Chunk:将文本(或其它数据)切分为每一段数据,是一种数据切片的方法
- Embedding:将每个 Chunk 转换为向量,是一种将高维空间的数据(文字、图片等)转换为低维空间的表示方法,后续可以通过匹配向量之间的余弦相似度来实现语义检索
- Vector Database:向量数据库,用于存储 Embedding 和原始 Chunk 的数据库(注意:某些 Vector Database 只支持存储 Embedding,需要自行来建立 Embedding 和原始 Chunk 之间的映射关系)
构建 RAG 向量知识库的过程

1、原始数据(Resource Data)
从各种来源收集原始数据,比如公司私有组件库的文档文本。
2、分块(Chunking)
将资源数据细分为更小的快,称为 Chunk。
3、向量化(Embedding)
将每个 Chunk 转换为向量表示,便于后续根据向量进行语义相似度匹配。
4、存储至向量数据库
将所有的 Chunk 和 Embedding 一一对应存储在向量数据库中,用于后续向量匹配检索出原始的 Chunk 数据。
RAG 向量检索过程的简单示例

1、用户输入一个问题,如:帮我生成一个 table,包括姓名、年龄、性别。
2、将问题转换为向量表示。
3、将用户需求的向量和向量数据库中的向量进行相似度匹配,检索出相似度高的数据源(Retrieval)。
4、将检索出的数据源和用户需求的问题组合(Augmented),一起输入给大模型(Generation)。
如何使用 RAG
1、基于开源知识库平台快速使用 RAG
- Dify
2、基于 LLM 应用框架来上手 RAG
- OpenAI SDK
- Vercel AI SDK
RAG 知识库数据准备
有两个关键的点:
1、组件 Chunk 知识的完整性保证。
将单个私有组件的知识库数据放在单独的 md 文件中保存,每个 md 文件内容就是单个的 Chunk,如下:
table.md
<!-- 这里是 Table 组件的知识库数据 -->input.md
<!-- 这里是 Input 组件的知识库数据 -->2、Chunk 包含的组件的语义和功能是清晰的。
在知识库数据中,可以包含组件的功能描述、使用场景、组件的 API、代码示例等信息。
Q:直接把组件的完整代码放进去是否可以?
A:不建议,全量代码占用的上下文太多,尽管现阶段的 AI 已经支持了超大的上下文 Context,但是随着 Context 的长度增大,AI 的推理能力也会下降,容易抓不到问题的重点。
在这里,我将使用场景、组件的 API 放入知识库数据中,示例如下:
# Table
## When To Use(使用场景)
Table 组件用于展示数据,通常用于展示列表数据。
## API(组件的 API)
- data: Array<{ name: string, age: number }>
- columns: Array<{ title: string, dataIndex: string }>可以参考 Antd 的组件库文档编写规范,基本上直接可以拿过来作为 RAG 的知识库数据
1、Clone 私有组件库的 Repo 到本地,安装相关依赖。
git clone https://github.com/AI-FE/private-bizcomponent-website.git
pnpm install2、编写脚本 format-docs.js,将私有组件数据转换为合适的知识库数据格式。
cd packages/@private-basic-components
node ai-docs/format-docs.js在这个脚本中,会遍历 components 目录下的所有组件文档,从文档中收集组件的使用场景、组件的 API 作为知识库的原始数据。
const fs = require("fs");
const path = require("path");
const inputDirectory = path.join(__dirname, "../components");
const outputFileCSVPath = path.join(__dirname, "basic-components.txt");
const dataSources = [];
function saveToTxt() {
// 将dataSources中的内容拼接成一个字符串,每个内容之间用效果展示效果展示-split line效果展示效果展示-分割
const csvContent = dataSources.join(
"\n效果展示效果展示-split line效果展示效果展示-\n",
);
// 将csvContent转换为带BOM的UTF-8格式防止用excel打开时中文乱码
const csvWithBOM = `\ufeff${csvContent}`;
// 将csvWithBOM写入到outputFileCSVPath文件中
fs.writeFileSync(outputFileCSVPath, csvWithBOM, "utf8");
console.log("基础组件知识库文件已保存");
}
function collectDoc(content) {
// 从content中提取组件名称
const match = content.match(/\btitle\b:\s*(.*)/);
// 提取组件名称
const componentName = match?.[1]?.trim();
// 搜索API部分的开始位置
const apiStartIndex = content.search("## API");
// 搜索When To Use部分的开始位置
const descriptionIndex = content.search("## When To Use");
// 如果API或When To Use部分没有找到,则打印警告并返回
if (apiStartIndex === -1 || descriptionIndex === -1) {
console.warn(
`API or description section not found for component: ${componentName}`,
);
return;
}
// 提取API部分的内容
const firstHandleContent = content
.substring(apiStartIndex + "## API".length)
.trim();
// 提取When To Use部分的内容
const firstHandelDescriptionContent = content
.substring(descriptionIndex + "## When To Use".length)
.trim();
// 搜索API部分的结束位置
const apiEndIndex = firstHandleContent.search(/(?<!#)##(?!#)/);
// 搜索When To Use部分的结束位置
const descriptionEndIndex =
firstHandelDescriptionContent.search(/(?<!#)##(?!#)/);
// 提取API部分的内容
// 如果API部分的结束位置大于0,则提取API部分的内容,否则提取整个API部分的内容
const apiContent = firstHandleContent
.substring(0, apiEndIndex >= 0 ? apiEndIndex : undefined)
.trim();
// 如果When To Use部分的结束位置大于0,则提取When To Use部分的内容,否则提取整个When To Use部分的内容
const descriptionContent = firstHandelDescriptionContent
.substring(0, descriptionEndIndex >= 0 ? descriptionEndIndex : undefined)
.trim();
// 将API部分和When To Use部分的内容拼接成一个字符串
const csvFormat = `
The documentation for the ${componentName} basic UI components
<when-to-use>
${descriptionContent}
</when-to-use>
<API>
${apiContent}
</API>
`;
// 将csvFormat添加到dataSources中
dataSources.push(csvFormat);
}
function processFiles(directoryPath) {
// 读取目录下的所有文件
const files = fs.readdirSync(directoryPath);
// 遍历所有文件
files.forEach((file) => {
// 拼接文件路径
const filePath = path.join(directoryPath, file);
// 判断是否是目录
if (fs.statSync(filePath).isDirectory()) {
// 如果是子目录,则递归处理
processFiles(filePath);
} else if (file === "index.en-US.md") {
// 如果文件名是 "index-en-US.md",则读取内容并追加到输出文件
const content = fs.readFileSync(filePath, "utf8");
// 收集文档内容
collectDoc(content);
}
});
}
// 递归遍历目录并处理文件
function generatedDOC(directoryPath) {
processFiles(directoryPath);
saveToTxt();
console.log(
`Successfully generated API documentation to ${outputFileCSVPath}`,
);
}
// 开始处理文件
generatedDOC(inputDirectory);脚本执行完成之后,会在 ai-docs 目录下生成一个 basic-components.txt 文件。

在 basic-compontents.txt 中,包含 效果展示效果展示-split line 效果展示效果展示-,这是用来后续将组件的知识库数据切分到不同的 Chunk 中,保证每个 Chunk 中的组件知识都是完整的。
在 basic-componens.txt 中,包含 <when-to-use></when-to-use> 和<API></API> 标签,这个用来保证当前组件的语义和功能是清晰的。
使用 Dify 构建 RAG 应用
我们使用 Dify 构建 RAG 应用,支持基于私有组件库生成业务组件。
创建 RAG 知识库
配置 embedding 能力
在 302.ai 管理后台新建 RAG API:

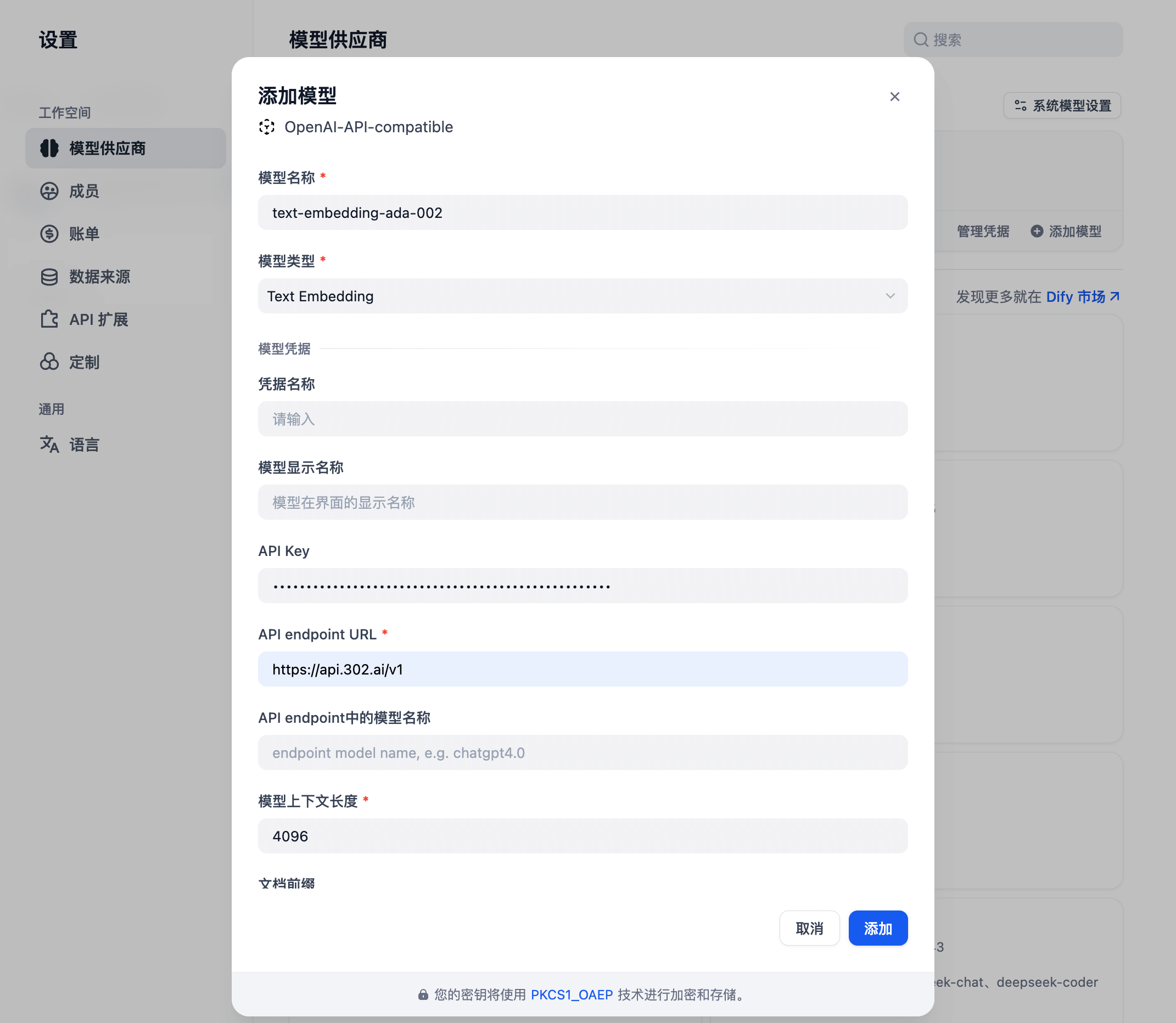
点击 302.ai 管理后台的 API 超市,分类 -> RAG 相关 -> OpenAI,选择 text-embedding-ada-002:

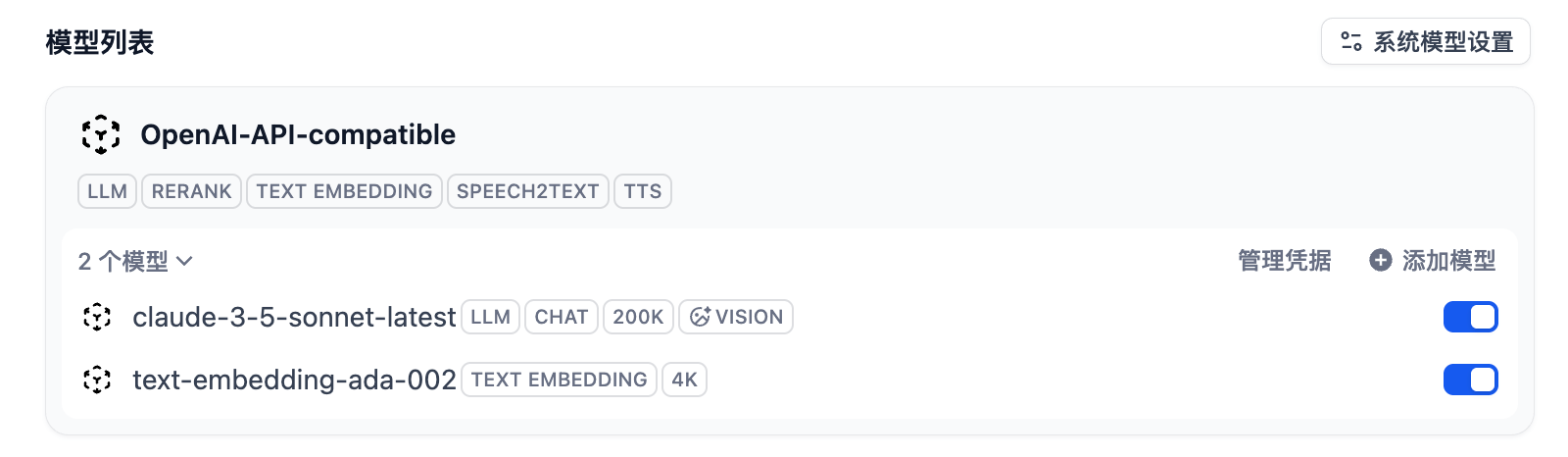
在 Dify 管理后台添加新的模型,text-embedding-ada-002:
私有组件库数据清洗
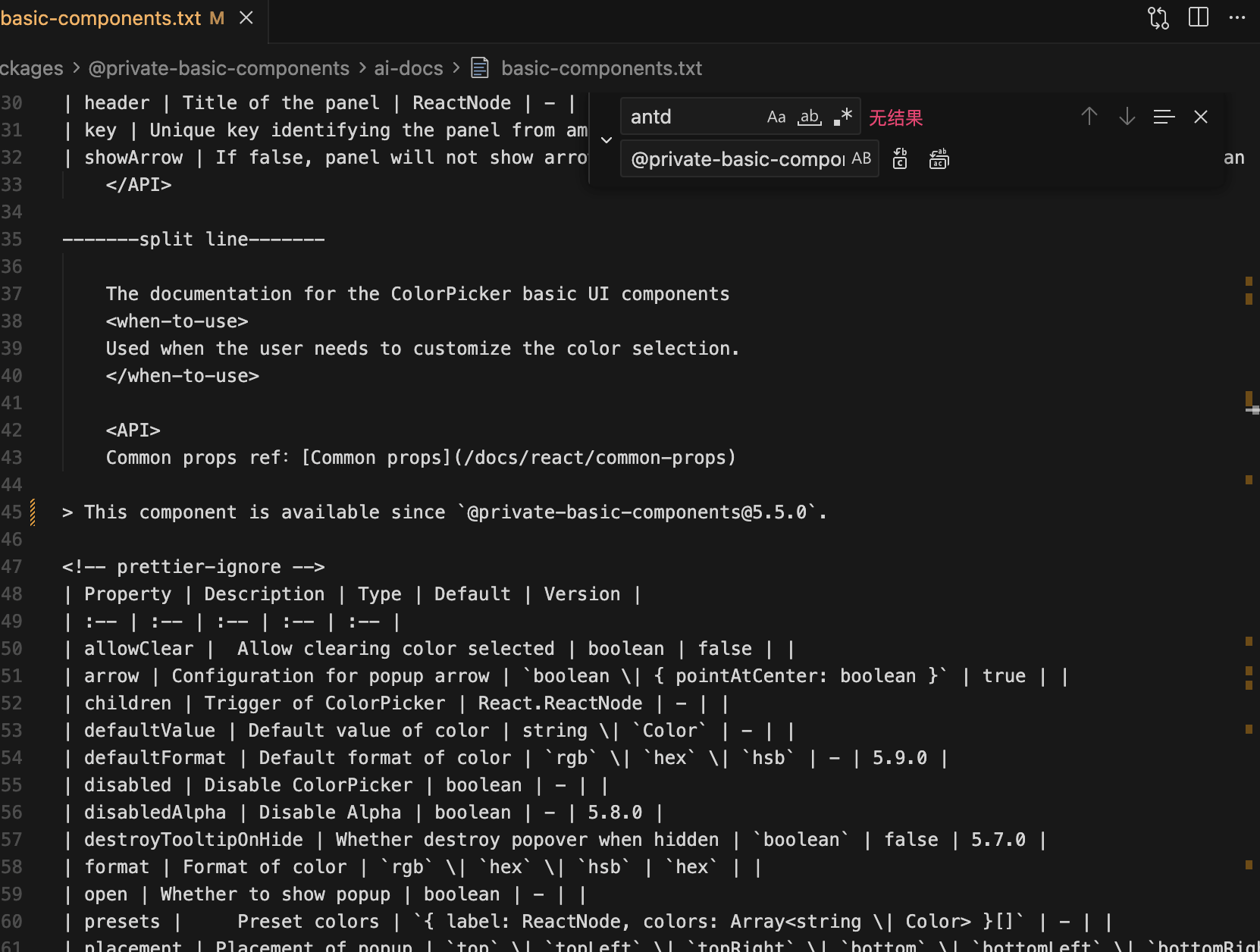
回到我们的前端项目,找到 basic-components.txt 文件,排除掉 antd 相关的内容,替换为 @private-basic-components:
新建知识库
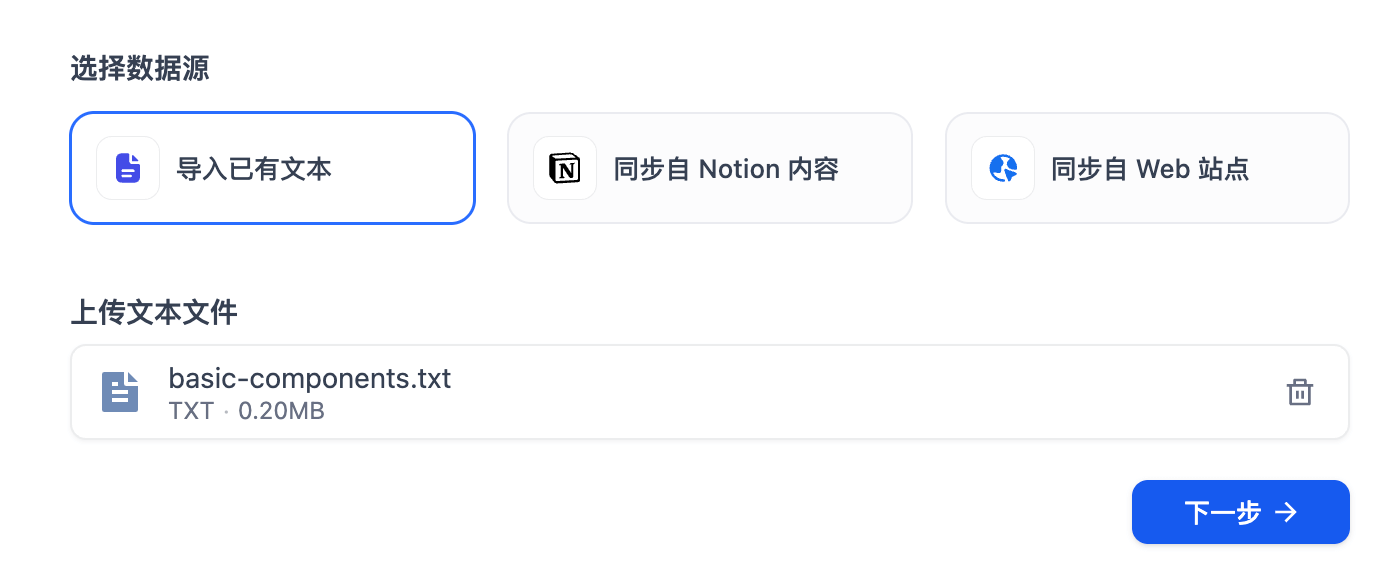
在 Dify 管理后台中,创建知识库,导入 basic-components.txt 文件,点击下一步。
注意,分段标识符填写 效果展示效果展示-split line 效果展示效果展示-,分段最大长度填写 4000,点击保存并处理。
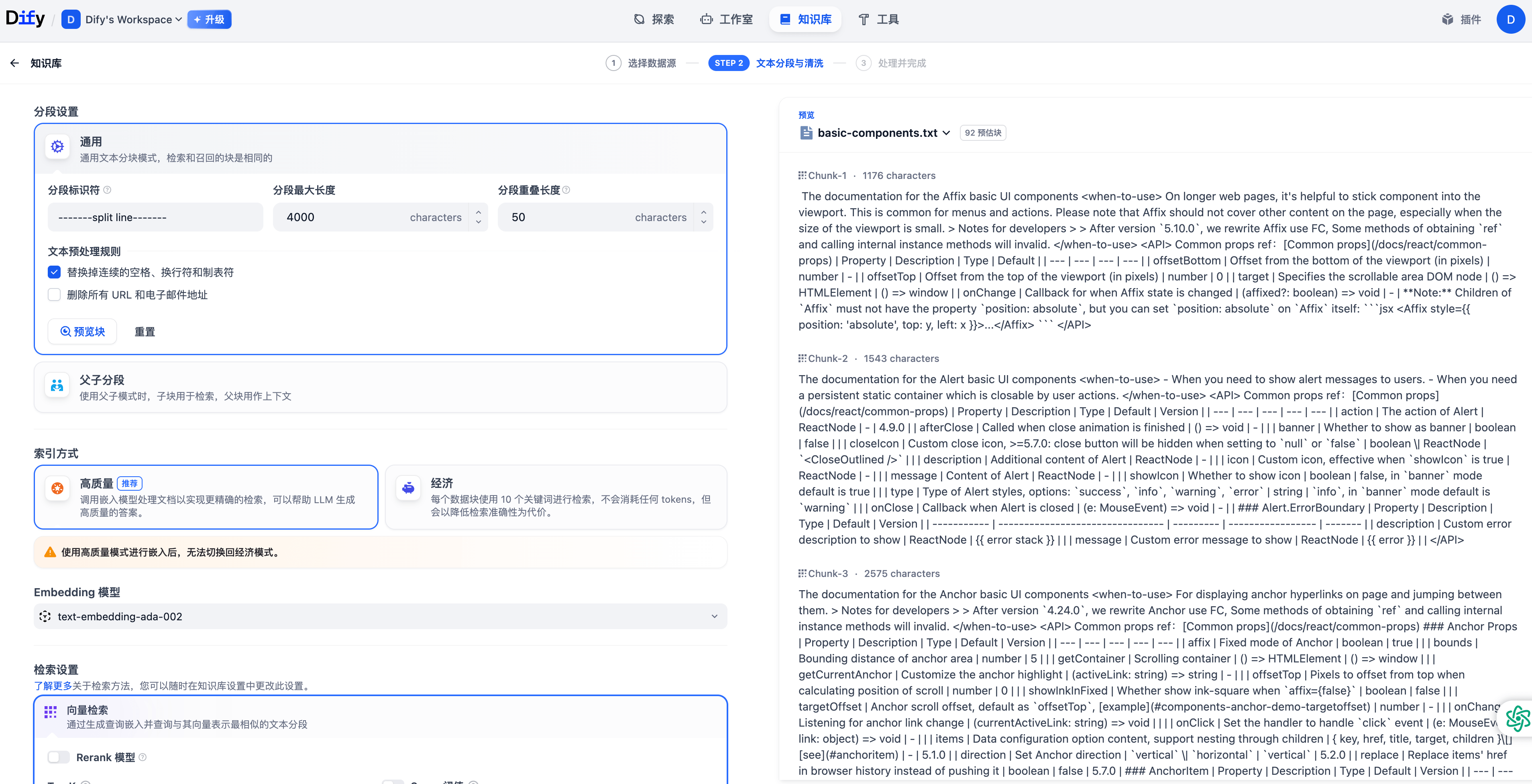
等待 Dify 处理,知识库创建完成。
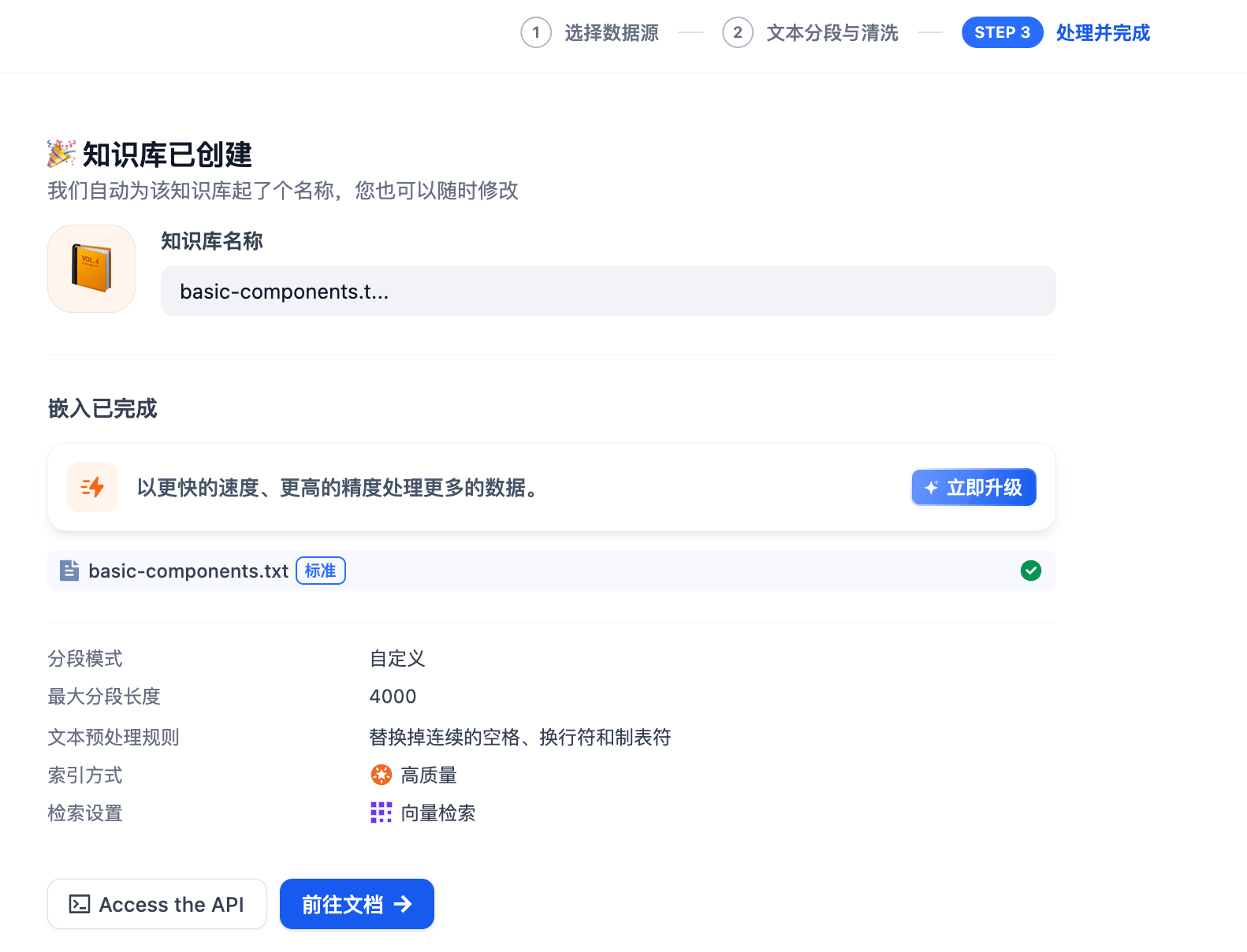
Retrieval 阶段测试
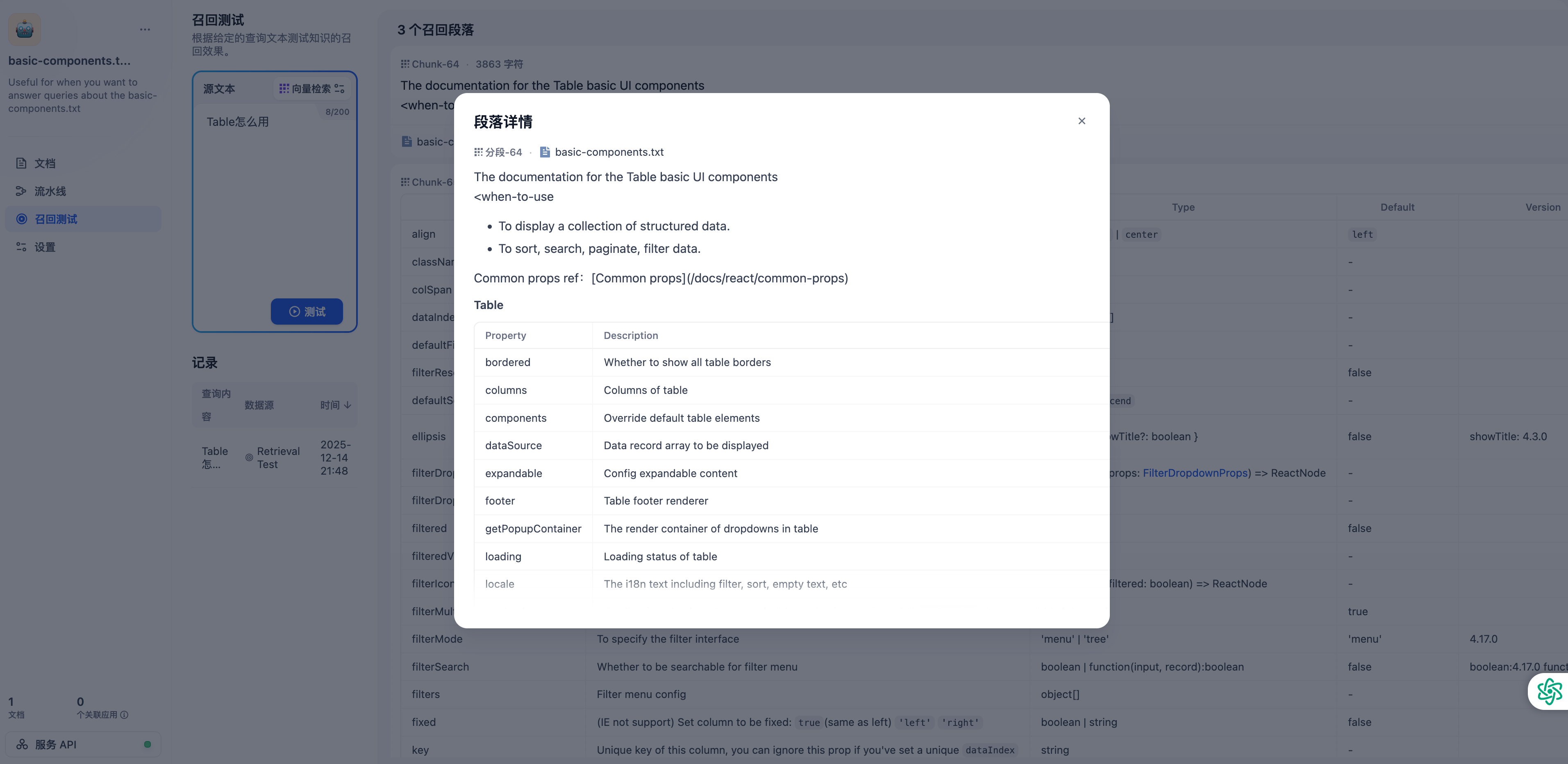
进入刚刚创建的知识库,点击召回测试,在源文本处输入 Table 怎么用,点击测试,查看召回效果。
集成 RAG 应用
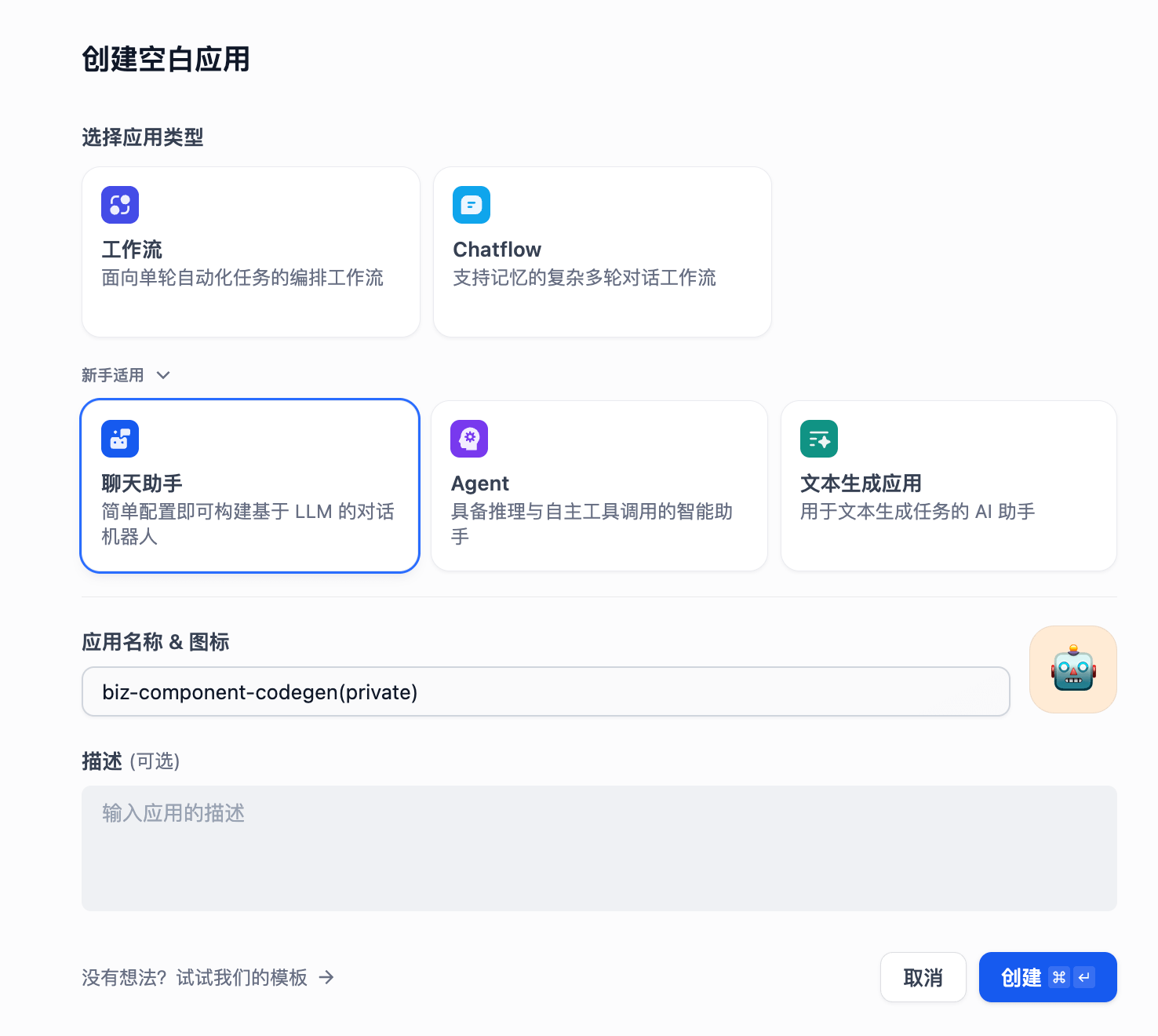
创建新应用
在 Dify 管理后台创建空白应用,选择聊天助手,输入应用名称:biz-component-codegen(private)。
写入提示词
进入 biz-component-codegen(private) 应用,写入提示词。
# Role: 前端业务组件开发专家
## Profile
- author: lv
- version: 0.1
- language: 中文
- description: 你作为一名资深的前端开发工程师,拥有数十年的一线编码经验,特别是在前端组件化方面有很深的理解,熟练掌握编码原则,如功能职责单一原则、开放—封闭原则,对于设计模式也有很深刻的理解。
## Goals
- 能够清楚地理解用户提出的业务组件需求.
- 根据用户的描述生成完整的符合代码规范的业务组件代码。
## Constraints
- 业务组件中用到的所有组件都来源于 `import { } from "@private-basic-components"` 组件库。
- 必须遵循知识库<API> </API>中组件的 props 来实现业务组件
## Workflows
第一步:结合用户需求理解我提供给你的`@private-basic-components`组件知识库数据。
- 我提供的知识库数据中,包含了实现这个需求可能需要的`@private-basic-components`组件知识。
- 其中`<when-to-use>`标签中,描述了组件的使用场景,`<API>`标签中,描述了组件的 props api 类型定义。
第二步:请根据用户的需求以及我提供的知识库数据,生成对应的业务组件代码,业务组件的规范模版如下:
组件包含 4 类文件,对应的文件名称和规则如下:
1、index.ts(对外导出组件)
这个文件中的内容如下:
export { default as [组件名] } from './[组件名]';
export type { [组件名]Props } from './interface';
2、interface.ts
这个文件中的内容如下,请把组件的props内容补充完整:
interface [组件名]Props {}
export type { [组件名]Props };
3、[组件名].stories.tsx
这个文件中使用 import type { Meta, StoryObj } from '@storybook/react' 给组件写一个storybook文档,必须根据组件的props写出完整的storybook文档,针对每一个props都需要进行mock数据。
4、[组件名].tsx
这个文件中存放组件的真正业务逻辑和样式,样式请用tailwindcss来编写
## Initialization
作为前端业务组件开发专家,你十分清晰你的[Goals],同时时刻记住[Constraints], 你将用清晰和精确的语言与用户对话,并按照[Workflows]逐步思考,逐步进行回答,竭诚为用户提供代码生成服务。关联创建的知识库
在 biz-component-codegen(private) 应用的知识库部分,添加我们之前创建好的知识库:basic-components.txt。
测试 Augmented、Generation 阶段测试
和 Bot 聊天,输入帮我生成一个 table,包含姓名、年龄、性别,测试 Augmented、Generation 阶段。

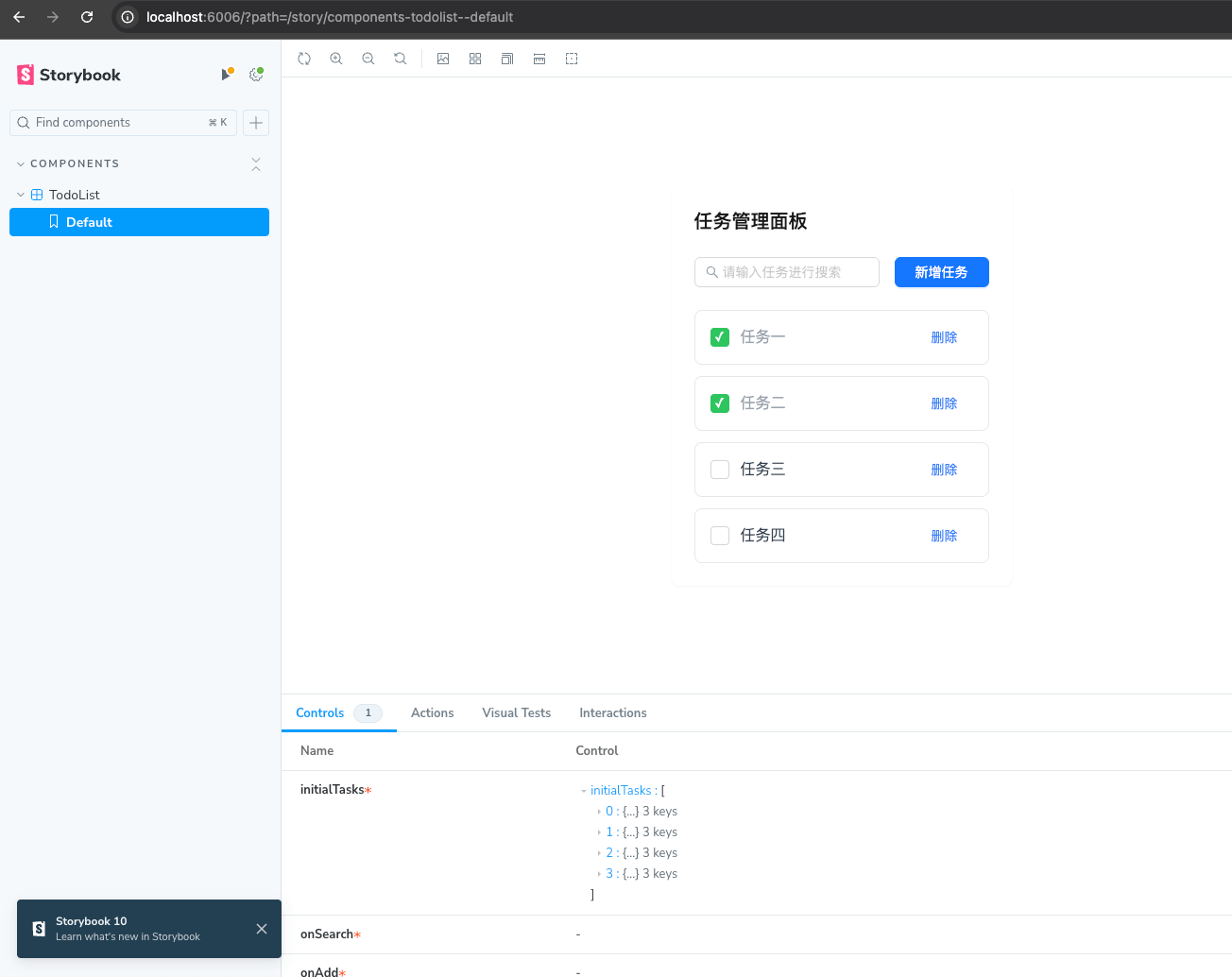
测试 RAG 应用
以上面的 TodoList 组件为例,上传图片,并输入:请用 Input、Button、Checkbox 实现这个组件。

把 Dify 应用生成的代码保存到我们的前端项目中。
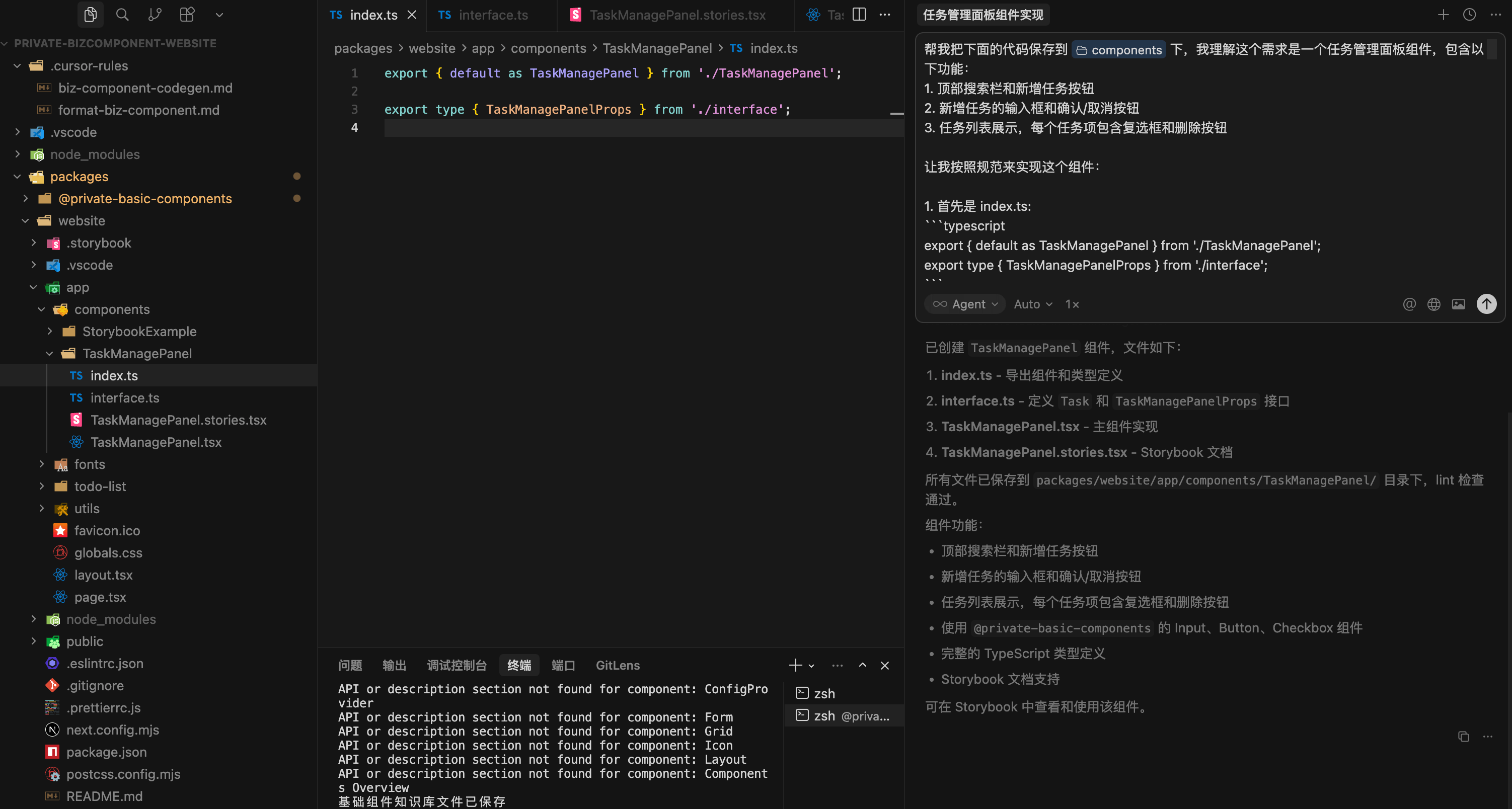
运行 pnpm storybook,查看演示效果。
经过 dify 上的操作,实现了一个简单的基于私有组件库生成业务组件的 RAG 应用,但是作为 AI 时代下的前端人员,如果想结合自己公司的工作流落地 AI,只掌握 Dify 这样的开源知识库平台,肯定是不够的,需要掌握市面上主流的 AI 研发技术栈,才能在实际业务中灵活落地更多的场景。
使用 OpenAI SDK、Vercel AI SDK 构建 RAG 应用
OpenAI SDK vs Vercel AI SDK
OpenAI SDK 是 OpenAI 官方提供的 AI SDK:
- 提供了直接访问 OpenAI API 的能力
- 集成了 chat、embedding、Fine-tuning 等
- 支持所有 OpenAI 系列的 LLM
- 支持三方中转 api(302、openrouter 等)
OpenAI SDK 更多资料详见官方文档:https://platform.openai.com/docs/overview
Vercel AI SDK 是一个专注于前端 AI 应用开发的工具包,特别适合构建基于 React、Next.js、Vue 等的全栈 AI 应用。
- 提供了一系列的 Hooks 和组件,用于快速构建 AI 应用
- 支持多种 LLM 模型,包括 OpenAI、Anthropic、Google 等
Vercel AI SDK 更多资料详见官方文档:https://sdk.vercel.ai/docs/introduction#why-use-the-ai-sdk
方案对比
| AI 框架 | 类比 UI 框架 | 类比说明 |
|---|---|---|
| OpenAI SDK | Tailwind CSS | - 基础的工具集(原子化的样式) - 灵活性高,可控性高,但需要自己组装 |
| Vercel AI SDK | Shadcn UI | - 在基础工具集的基础上,拓展了一些使用场景,比如支持多模型、hooks 机制 - 相比较 OpenAI SDK,拓展了更多的使用场景,学习成本、灵活性、可控性更高 |
项目架构

项目技术栈
- Next.js
- Ant Design
- Tailwind CSS
- TypeScript
- Drizzle ORM
- PostgreSQL
- OpenAI SDK
- Vercel AI SDK
项目目录结构
├── app
│ ├── api // api 路由
│ │ ├── openai
│ │ ├── vercelai
│ ├── components // 业务组件
│ ├── openai-sdk // 对接 OpenAI SDK 的 page
│ ├── vercel-ai // 对接 Vercel AI 的 page
│ ├── page.tsx // 入口
├── lib
│ ├── db // 数据库
│ │ ├── openai
│ │ │ ├── schema.ts
│ │ │ ├── selectors.ts
│ │ │ ├── actions.ts
│ │ ├── vercelai
│ │ │ ├── schema.ts
│ │ │ ├── selectors.ts
│ │ │ ├── actions.ts快速开始
clone 项目
git clone https://github.com/OweQian/private-component-codegen.gitinit 分支包含最基础的模版:
- 整个项目的基础架构、依赖包、基础工具
- 私有组件知识文档
- 项目中用到的业务组件
不包含:
- OpenAI SDK、Vercel AI SDK 的 RAG 实现
- 对接不同 RAG 逻辑的页面层
配置环境变量
cp .env.template .env编辑 .env 文件,配置环境变量
# 数据库连接字符串:从supabase中获取(https://supabase.com/)
DATABASE_URL=postgresql://
# 嵌入模型
EMBEDDING=text-embedding-ada-002
# 大模型 API Key
AI_KEY=sk-xxx
# 大模型 API Base URL
AI_BASE_URL=https://api
# 大模型
MODEL=claude-3-5-sonnet-latest启动项目
# pnpm version >= 9
pnpm install
# 启动storybook业务组件文档
pnpm storybook
# 启动项目
pnpm dev效果展示


OpenAI SDK
实现 Embedding
1、数据库表初始化
新建 lib/db/openai/schema.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
使用 drizzle-orm/pg-core 创建一个 PostgreSQL 数据表 schema,用于存储 OpenAI embeddings。表名为 'open_ai_embeddings',包含以下字段:
- id: 使用 nanoid 生成的主键,varchar(191) 类型
- content: 文本内容,text 类型,不允许为空
- embedding: 向量类型字段,维度为 1536,不允许为空
同时需要创建一个使用 HNSW 算法的向量索引,用于余弦相似度搜索。import { nanoid } from "nanoid";
import { index, pgTable, text, varchar, vector } from "drizzle-orm/pg-core";
/**
* OpenAI embeddings 表
*/
export const openAiEmbeddings = pgTable(
"open_ai_embeddings",
{
/**
* 唯一标识
*/
id: varchar("id", { length: 191 })
.primaryKey()
.$defaultFn(() => nanoid()),
/**
* 内容
*/
content: text("content").notNull(),
/**
* 嵌入向量
*/
embedding: vector("embedding", { dimensions: 1536 }).notNull(),
},
(table) => ({
/**
* 索引
*/
openAiEmbeddingIndex: index("open_ai_embedding_index").using(
/**
* 索引方法
*/
"hnsw",
/**
* 索引操作
*/
table.embedding.op("vector_cosine_ops"),
),
}),
);执行数据库同步命令 - 生成迁移文件:
pnpm db:generate执行数据库同步命令 - 执行迁移
pnpm db:migrate注意:如果遇到以下错误:PostgresError:type “vector” does not exist
请在 supabase 的 sql 编辑器中执行以下命令:CREATE EXTENSION IF NOT EXISTS vector;
查看 private-component-codegen 数据库,存在一张新表 open_ai_embeddings。

2、数据库 action
新建 lib/db/openai/action.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
创建一个 server action function,能够接收外部的数据源,保存到 db 中,function 入参是:embeddings: Array<{ embedding: number[]; content: string }>,生成的代码写到 action.ts 中。"use server";
import { db } from "..";
import { openAiEmbeddings as embeddingsTable } from "./schema";
export const createResource = async (
embeddings: Array<{ embedding: number[]; content: string }>,
) => {
try {
/**
* 插入嵌入向量
*/
await db.insert(embeddingsTable).values(
embeddings.map((embedding) => ({
...embedding,
})),
);
return "Resource successfully created and embedded.";
} catch (error) {
console.log("error", error);
return error instanceof Error && error.message.length > 0
? error.message
: "Error, please try again.";
}
};3、保存到数据库
新建 app/api/openai/embedding.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
使用 OpenAI SDK 创建一个函数,将输入的文本字符串转换为向量嵌入(embeddings)。支持将文本按特定分隔符分块处理,分隔符的默认值为 '效果展示效果展示-split line效果展示效果展示-',每个文本块都生成对应的 embedding 向量,并返回包含原文本和向量的结果数组。import { env } from "@/lib/env.mjs";
import OpenAI from "openai";
import { HttpsProxyAgent } from "https-proxy-agent";
const embeddingAI = new OpenAI({
apiKey: env.AI_KEY,
baseURL: env.AI_BASE_URL,
/**
* 代理配置
*/
...(env.HTTP_AGENT ? { httpAgent: new HttpsProxyAgent(env.HTTP_AGENT) } : {}),
});
const generateChunks = (input: string): string[] => {
return input.split("-------split line-------");
};
/**
* 生成嵌入向量
* @param value 输入文本
* @returns 嵌入向量
*/
export const generateEmbeddings = async (
value: string,
): Promise<Array<{ embedding: number[]; content: string }>> => {
const chunks = generateChunks(value);
const embeddings = await Promise.all(
chunks.map(async (chunk) => {
/**
* 生成嵌入向量
*/
const response = await embeddingAI.embeddings.create({
model: env.EMBEDDING,
input: chunk,
});
return {
content: chunk,
embedding: response.data[0].embedding,
};
}),
);
return embeddings;
};新建 app/api/openai/embedDocs.ts 文件,将私有组件知识库文档嵌入到数据库中。
import fs from "fs";
import { env } from "@/lib/env.mjs";
import { createResource } from "@/lib/db/openai/actions";
import { generateEmbeddings } from "./embedding";
console.log("env.EMBEDDING", env.EMBEDDING);
/**
* 入库
*/
export const generateEmbeddingsFromDocs = async () => {
console.log("start reading docs");
/**
* 读取文档
*/
const docs = fs.readFileSync("./ai-docs/basic-components.txt", "utf8");
console.log("start generating embeddings");
/**
* 生成嵌入向量
*/
const embeddings = await generateEmbeddings(docs);
console.log("start creating resource");
/**
* 创建资源,插入到数据库表
*/
await createResource(embeddings);
console.log("success~~~");
};
generateEmbeddingsFromDocs();添加 scripts 命令:
"openai:embedDocs": "tsx app/api/openai/embedDocs.ts"执行命令:
pnpm openai:embedDocs
查看 private-component-codegen 数据库,此时在 open_ai_embeddings 表中已经能看到我们插入的内容。

实现 RAG API 逻辑
1、数据库向量相似度查询
新建 lib/db/openai/selectors.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码
创建一个基于向量嵌入的语义相似度搜索函数。该函数需要:
- 接收一个查询向量(embedding)作为输入
- 计算输入向量与数据库中存储的向量之间的余弦相似度
- 筛选出相似度高于指定阈值的结果
- 返回相似度最高的 N 个结果,包含原始内容和相似度分数
- 使用 SQL ORM 实现数据库查询"use server";
import { cosineDistance } from "drizzle-orm/sql";
import { openAiEmbeddings } from "./schema";
import { db } from "@/lib/db";
import { sql, gt, desc } from "drizzle-orm";
export const findSimilarContent = async (userQueryEmbedded: number[]) => {
/**
* 计算相似度
*/
const similarity = sql<number>`1 - (${cosineDistance(
openAiEmbeddings.embedding,
userQueryEmbedded,
)})`;
/**
* 查找相关内容
*/
const similarGuides = await db
.select({
content: openAiEmbeddings.content,
similarity,
})
.from(openAiEmbeddings)
.where(gt(similarity, 0.5))
.orderBy((t) => desc(t.similarity))
.limit(4);
return similarGuides;
};2、针对单条 message 的 Embedding 函数
在 app/api/openai/embedding.ts 中添加函数:
/**
* 生成单个嵌入向量
* @param value 输入文本
* @returns 嵌入向量
*/
export const generateEmbedding = async (value: string): Promise<number[]> => {
const input = value.replaceAll("\\n", " ");
const response = await embeddingAI.embeddings.create({
model: env.EMBEDDING,
input,
});
return response.data[0].embedding;
};3、检索向量数据库并召回函数
在 app/api/openai/embedding.ts 中添加函数:
/**
* 查找相关内容
* @param userQuery 用户查询
* @returns 相关内容
*/
export const findRelevantContent = async (
userQuery: string,
): Promise<{ content: string; similarity: number }[]> => {
const userQueryEmbedded = await generateEmbedding(userQuery);
return findSimilarContent(userQueryEmbedded);
};4、新建 RAG API 路由
新建 app/api/openai/types.ts 文件,定义 RAG API 的请求体。
import { ChatCompletionMessageParam } from "openai/resources/chat/completions";
export type OpenAIRequest = {
messages: ChatCompletionMessageParam[];
};新建 app/api/openai/route.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
创建一个基于 Next.js 的流式 AI 对话 API 路由处理器,使用 OpenAI API 实现。该接口需要实现以下功能:
1. 通过 POST 请求接收对话消息
2. 基于最后一条消息使用向量嵌入(embeddings)查找相关内容
3. 创建 OpenAI 的流式对话补全,要求:
- 将相关内容整合到系统提示词中
- 使用服务器发送事件(SSE)进行流式响应
- 在流中同时返回 AI 响应片段和相关内容/**
* OpenAI API 路由处理文件
*
* 该文件实现了基于 RAG(检索增强生成)的聊天 API 端点,主要功能包括:
* 1. 接收聊天消息请求
* 2. 通过向量检索查找相关内容(RAG)
* 3. 调用 OpenAI API 生成流式响应
* 4. 以 Server-Sent Events (SSE) 格式返回结果
*/
import OpenAI from "openai";
import { HttpsProxyAgent } from "https-proxy-agent";
import { OpenAIRequest } from "./types";
import { ChatModel } from "openai/resources/index.mjs";
import { findRelevantContent } from "./embedding";
import { getSystemPrompt } from "@/lib/prompt";
import { env } from "@/lib/env.mjs";
/**
* 创建 SSE (Server-Sent Events) 格式的数据块
*
* @param relevantContent - 检索到的相关内容数组,包含内容和相似度分数
* @param aiResponse - AI 响应的文本内容(通常是流式响应中的增量内容)
* @returns 编码后的 SSE 格式数据(UTF-8 字节数组)
*/
const createEnqueueContent = (
relevantContent: Array<{ content: string; similarity: number }>,
aiResponse: string,
) => {
const data = {
relevantContent: relevantContent || [],
aiResponse: aiResponse || "",
};
// 将数据编码为 SSE 格式:event: message\ndata: {...}\n\n
return new TextEncoder().encode(
`event: message\ndata: ${JSON.stringify(data)}\n\n`,
);
};
/**
* POST 请求处理函数
*
* 处理聊天请求,执行以下步骤:
* 1. 解析请求体获取消息列表
* 2. 初始化 OpenAI 客户端(支持代理配置)
* 3. 提取最后一条消息内容用于 RAG 检索
* 4. 通过向量检索查找相关内容
* 5. 构建包含系统提示词的消息列表
* 6. 调用 OpenAI API 获取流式响应
* 7. 将响应转换为 SSE 流返回给客户端
*
* @param req - HTTP 请求对象
* @returns 包含 SSE 流的 Response 对象,或错误响应
*/
export async function POST(req: Request) {
const request: OpenAIRequest = await req.json();
const { messages } = request;
try {
// 初始化 OpenAI 客户端
// 支持通过环境变量配置代理(用于需要代理访问的场景)
const openai = new OpenAI({
apiKey: env.AI_KEY,
baseURL: env.AI_BASE_URL,
...(env.HTTP_AGENT
? { httpAgent: new HttpsProxyAgent(env.HTTP_AGENT) }
: {}),
});
// 获取最后一条消息(用户的最新输入)
const lastMessage = messages[messages.length - 1];
// 提取最后一条消息的文本内容
// 支持两种格式:字符串或消息内容对象数组
const lastMessageContentString =
Array.isArray(lastMessage.content) && lastMessage.content.length > 0
? lastMessage.content
.map((c) => (c.type === "text" ? c.text : ""))
.join("")
: (lastMessage.content as string);
// 通过向量检索查找与用户输入相关的内容(RAG)
const relevantContent = await findRelevantContent(lastMessageContentString);
console.log("relevantContent", relevantContent);
// 创建 OpenAI 聊天完成请求
// 使用流式响应以支持实时返回结果
const result = openai.chat.completions.create({
model: (env.MODEL as ChatModel) || "gpt-4o",
max_tokens: 4096,
stream: true, // 启用流式响应
messages: [
{
role: "system",
// 将检索到的相关内容注入到系统提示词中
content: getSystemPrompt(
relevantContent.map((c) => c.content).join("\n"),
),
},
...messages, // 包含用户的历史消息
],
});
// 捕获创建请求时的错误
await result.catch((error) => {
throw error;
});
// 创建可读流,用于将 OpenAI 的流式响应转换为 SSE 格式
const stream = new ReadableStream({
async start(controller) {
try {
// 遍历 OpenAI 返回的流式数据块
for await (const chunk of await result) {
// 将每个数据块编码为 SSE 格式并加入队列
controller.enqueue(
createEnqueueContent(
relevantContent, // 每次响应都包含检索到的相关内容
chunk?.choices?.[0]?.delta?.content || "", // 提取增量内容
),
);
}
} catch (err) {
console.error("Stream error:", err);
controller.error(err);
} finally {
// 确保流被正确关闭
controller.close();
}
},
cancel() {
// 处理流被取消的情况
console.log("Stream cancelled");
},
});
// 返回 SSE 格式的响应
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream", // SSE 内容类型
"Cache-Control": "no-cache", // 禁用缓存
Connection: "keep-alive", // 保持连接活跃
},
});
} catch (error: unknown) {
// 错误处理:返回 400 错误响应
console.error("error catch", error);
if (error instanceof Error) {
return new Response(error.message, {
status: 400,
statusText: "Bad Request",
});
}
return new Response("An unknown error occurred", {
status: 400,
statusText: "Bad Request",
});
}
}对接 RAG API
1、补全 OpenAI SDK 的业务组件
打开 app/openai-sdk/index.tsx 文件。
"use client";
import { ChatMessages } from "../components/ChatMessages";
const Home = () => {
return (
<ChatMessages
messages={[]}
input={""}
handleInputChange={() => {}}
onSubmit={() => {}}
isLoading={false}
messageImgUrl={""}
setMessagesImgUrl={() => {}}
onRetry={() => {}}
/>
);
};
export default Home;2、让 AI 基于业务组件和 API 进行数据对接和联调
打开 app/openai-sdk/index.tsx 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
对接 OpenAI API 数据"use client";
/**
* OpenAI SDK 聊天界面组件
*
* 该组件实现了与 OpenAI API 的交互,支持:
* - 文本和图片消息的发送
* - 流式响应(SSE)的接收和处理
* - RAG(检索增强生成)相关文档的显示
* - 消息重试功能
*/
import { useState } from "react";
import { nanoid } from "nanoid";
import { Message } from "../components/ChatMessages/interface";
import ChatMessages from "../components/ChatMessages/ChatMessages";
import { OpenAIRequest } from "../api/openai/types";
const Home = () => {
// 用户输入的文本内容
const [input, setInput] = useState("");
// 聊天消息列表
const [messages, setMessages] = useState<Message[]>([]);
// 消息中附加的图片 URL
const [messageImgUrl, setMessageImgUrl] = useState("");
// 是否正在加载(发送请求或接收响应中)
const [isLoading, setIsLoading] = useState(false);
/**
* 处理输入框内容变化
* @param e - 输入框的 change 事件
*/
const handleInputChange = (e: React.ChangeEvent<HTMLInputElement>) => {
setInput(e.target.value);
};
/**
* 发送消息到 OpenAI API 并处理流式响应
*
* 该函数执行以下操作:
* 1. 更新消息列表并设置加载状态
* 2. 发送 POST 请求到 /api/openai
* 3. 使用 ReadableStream 读取 SSE(Server-Sent Events)流式响应
* 4. 解析每个数据块,提取 AI 响应和 RAG 相关文档
* 5. 实时更新消息内容
*
* @param newMessages - 包含新用户消息的完整消息列表
*/
const handleSendMessage = async (newMessages: Message[]) => {
try {
// 更新消息列表(包含用户刚发送的消息)
setMessages(newMessages as Message[]);
setIsLoading(true);
// 发送请求到 OpenAI API
const response = await fetch("/api/openai", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
messages: newMessages,
} as OpenAIRequest),
});
// 获取流式响应的读取器
const reader = response?.body?.getReader();
console.log("reader", reader, response);
const textDecoder = new TextDecoder();
// 累积接收到的 AI 响应文本
let received_stream = "";
// 为助手消息生成唯一 ID
const id = nanoid();
// 缓冲区,用于处理不完整的 SSE 消息
let buffer = "";
// 循环读取流式数据
while (true) {
if (!reader) break;
const { done, value } = await reader.read();
// 如果流结束,退出循环
if (done) {
break;
}
// 将新的数据块添加到缓冲区
buffer += textDecoder.decode(value, { stream: true });
// SSE 消息以 \n\n 分隔,处理缓冲区中的所有完整消息
const messages = buffer.split("\n\n");
// 保留最后一个不完整的消息在缓冲区中,等待下次数据到达
buffer = messages.pop() || "";
// 处理每个完整的 SSE 消息
for (const message of messages) {
if (!message.trim()) continue;
// SSE 格式:每行一个字段,data: 行包含实际数据
const lines = message.split("\n");
const dataLine = lines.find((line) => line.startsWith("data:"));
if (dataLine) {
// 提取 data: 后的 JSON 数据
const jsonData = dataLine.slice(5).trim();
try {
// 解析 JSON,包含 AI 响应和 RAG 相关文档
const { relevantContent, aiResponse } = JSON.parse(jsonData) as {
relevantContent: Array<{ content: string; similarity: number }>;
aiResponse: string;
};
// 累积 AI 响应文本
received_stream += aiResponse;
// 更新消息列表
setMessages((messages) => {
// 如果助手消息已存在,更新它
if (messages.find((message) => message.id === id)) {
return messages.map((message) => {
if (message.id === id) {
return {
...message,
content: received_stream,
// 将 RAG 相关文档转换为消息格式
ragDocs: relevantContent.map(
({ content, similarity }) => ({
id: nanoid(),
content: content,
score: similarity,
}),
),
};
}
return message;
});
}
// 如果助手消息不存在,创建新消息
return [
...messages,
{
id,
role: "assistant",
content: received_stream,
ragDocs: relevantContent.map(({ content, similarity }) => ({
id: nanoid(),
content: content,
score: similarity,
})),
},
];
});
} catch (e) {
console.error("Error parsing SSE data:", e);
}
}
}
}
// 清空输入框和图片 URL,结束加载状态
setInput("");
setMessageImgUrl("");
setIsLoading(false);
} catch (error) {
console.error(error);
setIsLoading(false);
// 如果请求失败,且最后一条消息是用户消息,则移除它
// 这样可以避免在界面上显示未得到响应的用户消息
setMessages((messages) =>
messages.length > 0 && messages[messages.length - 1].role === "user"
? messages.slice(0, -1)
: messages,
);
}
};
/**
* 处理表单提交
*
* 将用户输入(文本和可选的图片)添加到消息列表并发送
* 如果存在图片 URL,则创建多模态消息(包含图片和文本)
*/
const handleSubmit = async () => {
await handleSendMessage([
...messages,
{
id: nanoid(),
role: "user",
// 如果有图片,创建多模态消息格式;否则只发送文本
content: messageImgUrl
? [
{ type: "image_url", image_url: { url: messageImgUrl } },
{ type: "text", text: input },
]
: input,
},
]);
};
/**
* 重试指定消息
*
* 从消息列表中移除指定消息及其之后的所有消息,
* 然后重新发送该消息之前的所有消息
*
* @param id - 要重试的消息 ID
*/
const handleRetry = (id: string) => {
const index = messages.findIndex((message) => message.id === id);
// 如果找到消息且不是第一条,则重试
if (index > 0) {
// 获取该消息之前的所有消息
const previousMessages = messages.slice(0, index);
handleSendMessage(previousMessages);
}
};
return (
<ChatMessages
messages={messages}
input={input}
handleInputChange={handleInputChange}
onSubmit={handleSubmit}
isLoading={isLoading}
messageImgUrl={messageImgUrl}
setMessagesImgUrl={setMessageImgUrl}
onRetry={handleRetry}
/>
);
};
export default Home;效果展示

查看 RAG Docs:

Vercel AI SDK
实现 Embedding
复制一份 lib/db/openai 文件夹,重命名为 lib/db/vercelai。
1、数据库表初始化
修改 lib/db/vercelai/schema.ts,将 openai 替换为 vercelai。
import { nanoid } from "nanoid";
import { index, pgTable, text, varchar, vector } from "drizzle-orm/pg-core";
/**
* Vercel AI embeddings 表
*/
export const vercelAiEmbeddings = pgTable(
"vercel_ai_embeddings",
{
/**
* 唯一标识
*/
id: varchar("id", { length: 191 })
.primaryKey()
.$defaultFn(() => nanoid()),
/**
* 内容
*/
content: text("content").notNull(),
/**
* 嵌入向量
*/
embedding: vector("embedding", { dimensions: 1536 }).notNull(),
},
(table) => ({
/**
* 索引
*/
vercelAiEmbeddingIndex: index("vercel_ai_embedding_index").using(
/**
* 索引方法
*/
"hnsw",
/**
* 索引操作
*/
table.embedding.op("vector_cosine_ops"),
),
}),
);2、数据库 action
修改 lib/db/vercelai/actions.ts:
"use server";
import { db } from "..";
import { vercelAiEmbeddings as embeddingsTable } from "./schema";
export const createResource = async (
embeddings: Array<{ embedding: number[]; content: string }>,
) => {
try {
/**
* 插入嵌入向量
*/
await db.insert(embeddingsTable).values(
embeddings.map((embedding) => ({
...embedding,
})),
);
return "Resource successfully created and embedded.";
} catch (error) {
console.log("error", error);
return error instanceof Error && error.message.length > 0
? error.message
: "Error, please try again.";
}
};执行数据库同步命令:
pnpm db:generate
pnpm db:migrate查看 private-component-codegen 数据库,存在一张新表 vercel_ai_embeddings。

3、保存到数据库
新建 app/api/vercel/embedding.ts 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
请使用 vercel ai sdk 重构 @app/api/openai/embedding.ts 中的代码,保存到@app/api/vercelai/embedding.ts 下import { env } from "@/lib/env.mjs";
import { embed, embedMany } from "ai";
import { findSimilarContent } from "@/lib/db/vercelai/selector";
import { model } from "./settings";
const embeddingModel = model.embedding(env.EMBEDDING);
const generateChunks = (input: string): string[] => {
return input
.trim()
.split("-------split line-------")
.filter((chunk) => chunk !== "");
};
/**
* 生成嵌入向量
* @param value 输入文本
* @returns 嵌入向量
*/
export const generateEmbeddings = async (
value: string,
): Promise<Array<{ embedding: number[]; content: string }>> => {
const chunks = generateChunks(value);
// 使用 AI SDK 的 embedMany 函数来批量生成 embeddings
const { embeddings } = await embedMany({
model: embeddingModel,
values: chunks,
});
return embeddings.map((embedding, i) => ({
content: chunks[i],
embedding,
}));
};
/**
* 生成单个嵌入向量
* @param value 输入文本
* @returns 嵌入向量
*/
export const generateEmbedding = async (value: string): Promise<number[]> => {
const input = value.replaceAll("\\n", " ");
// 使用 AI SDK 的 embed 函数来生成单个 embedding
const { embedding } = await embed({
model: embeddingModel,
value: input,
});
return embedding;
};
/**
* 查找相关内容
* @param userQuery 用户查询
* @returns 相关内容
*/
export const findRelevantContent = async (
userQuery: string,
): Promise<{ content: string; similarity: number }[]> => {
const userQueryEmbedded = await generateEmbedding(userQuery);
return findSimilarContent(userQueryEmbedded);
};复制 app/api/openai/embedDocs.ts 文件到 app/api/vercelai/embedDocs.ts。
import fs from "fs";
import { env } from "@/lib/env.mjs";
import { createResource } from "@/lib/db/vercelai/actions";
import { generateEmbeddings } from "./embedding";
console.log("env.EMBEDDING", env.EMBEDDING);
/**
* 入库
*/
export const generateEmbeddingsFromDocs = async () => {
console.log("start reading docs");
/**
* 读取文档
*/
const docs = fs.readFileSync("./ai-docs/basic-components.txt", "utf8");
console.log("start generating embeddings");
/**
* 生成嵌入向量
*/
const embeddings = await generateEmbeddings(docs);
console.log("start creating resource");
/**
* 创建资源,插入到数据库表
*/
await createResource(embeddings);
console.log("success~~~");
};
generateEmbeddingsFromDocs();添加 scripts 命令:
"vercelai:embedDocs": "tsx app/api/vercelai/embedDocs.ts"执行命令:
pnpm vercelai:embedDocs
查看 private-component-codegen 数据库,此时在 vercel_ai_embeddings 表中已经能看到我们插入的内容。

实现 RAG API 逻辑
修改 lib/db/vercelai/selector.ts。
"use server";
import { cosineDistance } from "drizzle-orm/sql";
import { vercelAiEmbeddings } from "./schema";
import { db } from "@/lib/db";
import { sql, gt, desc } from "drizzle-orm";
export const findSimilarContent = async (userQueryEmbedded: number[]) => {
/**
* 计算相似度
*/
const similarity = sql<number>`1 - (${cosineDistance(
vercelAiEmbeddings.embedding,
userQueryEmbedded,
)})`;
/**
* 查找相关内容
*/
const similarGuides = await db
.select({
content: vercelAiEmbeddings.content,
similarity,
})
.from(vercelAiEmbeddings)
.where(gt(similarity, 0.5))
.orderBy((t) => desc(t.similarity))
.limit(4);
return similarGuides;
};复制 app/api/openai/route.ts、app/api/openai/types.ts 到 app/api/vercelai 下。
让 cursor agent composer 基于以下 prompt 生成代码:
请帮我把 @route.ts @types.ts 重构为使用 vercel ai sdk streamText 的代码生成的代码:
import { CoreMessage, createDataStreamResponse, streamText } from "ai";
import { OpenAIRequest } from "./types";
import { findRelevantContent } from "./embedding";
import { getSystemPrompt } from "@/lib/prompt";
import { env } from "@/lib/env.mjs";
import { ChatCompletionMessageParam } from "openai/resources/chat/completions.mjs";
import { model } from "./settings";
/**
* 将 OpenAI 格式的消息转换为 AI SDK 的 CoreMessage 格式
* 主要处理图片内容的格式转换,将 image_url 类型转换为 image 类型,并移除 base64 前缀
*
* @param messages - OpenAI 格式的消息数组
* @returns 转换后的 CoreMessage 数组
*/
export const formatMessages = (messages: ChatCompletionMessageParam[]) => {
return messages.map((message) => {
return {
...message,
role: message.role,
// 处理消息内容:如果是数组格式(可能包含文本和图片),需要特殊处理
content: Array.isArray(message.content)
? message.content.map((content) => {
// 如果是图片 URL 类型,转换为 AI SDK 需要的格式
if (content.type === "image_url") {
return {
type: "image",
// 移除 base64 数据 URL 的前缀(data:image/xxx;base64,),只保留 base64 编码的图片数据
image: content.image_url.url.replace(
/^data:image\/\w+;base64,/,
"",
),
};
}
// 其他类型的内容直接返回
return {
...content,
};
})
: message.content,
};
}) as CoreMessage[];
};
// 根据环境变量中的模型名称创建模型实例
const openaiModel = model(env.MODEL);
/**
* 处理聊天完成的 POST 请求
* 实现 RAG(检索增强生成)功能:根据用户消息检索相关内容,然后生成回答
*
* @param req - HTTP 请求对象
* @returns 数据流响应,包含流式文本输出和相关内容注释
*/
export async function POST(req: Request) {
try {
// 解析请求体,获取消息列表
const request: OpenAIRequest = await req.json();
const { messages } = request;
// 获取最后一条用户消息(用于检索相关内容)
const lastMessage = messages[messages.length - 1];
// 提取最后一条消息的文本内容
// 如果内容是数组格式(可能包含多种类型),只提取文本类型的内容
const lastMessageContent = Array.isArray(lastMessage.content)
? lastMessage.content
.filter((c) => c.type === "text")
.map((c) => c.text)
.join("")
: (lastMessage.content as string);
// 使用向量检索查找与用户消息相关的内容(RAG 检索步骤)
const relevantContent = await findRelevantContent(lastMessageContent);
// 根据检索到的相关内容生成系统提示词
// 系统提示词会包含检索到的参考内容,帮助模型更好地回答用户问题
const system = getSystemPrompt(
relevantContent.map((c) => c.content).join("\n"),
);
// 创建数据流响应,支持流式输出
return createDataStreamResponse({
execute: async (dataStream) => {
// 将检索到的相关内容作为消息注释写入数据流
// 前端可以通过这些注释显示相关的参考文档
dataStream.writeMessageAnnotation({
relevantContent,
});
// 使用 AI SDK 的 streamText 生成流式文本响应
const result = streamText({
model: openaiModel, // 使用的 AI 模型
system, // 系统提示词(包含检索到的相关内容)
messages: formatMessages(messages), // 格式化后的消息列表
});
// 将文本流合并到数据流中,实现流式输出
result.mergeIntoDataStream(dataStream);
},
// 错误处理回调
onError: (error) => {
console.error("Error in chat completion:", error);
return error instanceof Error
? error.message
: "An unknown error occurred";
},
});
} catch (error: unknown) {
// 捕获并处理请求处理过程中的错误
console.error("Error in chat completion:", error);
return new Response(
error instanceof Error ? error.message : "An unknown error occurred",
{
status: 400,
statusText: "Bad Request",
},
);
}
}对接 RAG API
1、补全 Vercel AI SDK 的业务组件
打开 app/vercel-ai/index.tsx 文件。
"use client";
import { ChatMessages } from "../components/ChatMessages";
const Home = () => {
return (
<ChatMessages
messages={[]}
input={""}
handleInputChange={() => {}}
onSubmit={() => {}}
isLoading={false}
messageImgUrl={""}
setMessagesImgUrl={() => {}}
onRetry={() => {}}
/>
);
};
export default Home;2、让 AI 基于业务组件和 API 进行数据对接和联调
打开 app/vercel-ai/index.tsx 文件。
让 cursor agent composer 基于以下 prompt 生成代码:
请用 useChat 对接页面"use client";
/**
* Vercel AI SDK 聊天界面组件
*
* 使用 Vercel AI SDK 的 useChat hook 实现聊天功能,支持文本和图片输入
* 集成了 RAG(检索增强生成)功能,可以显示相关文档内容
*/
// Vercel AI SDK 提供的类型和 hook
import { Message, useChat } from "ai/react";
// 生成唯一 ID 的工具库
import { nanoid } from "nanoid";
// 聊天消息展示组件
import ChatMessages from "../components/ChatMessages/ChatMessages";
// React hooks
import { useState } from "react";
// RAG 文档类型定义
import { RAGDocument } from "../components/RAGDocsShow/interface";
/**
* 主页面组件
* 负责管理聊天状态、处理用户输入、发送消息到后端 API
*/
const Home = () => {
// 使用 Vercel AI SDK 的 useChat hook 管理聊天状态
const {
messages, // 当前所有消息列表
input, // 输入框的当前值
handleInputChange, // 处理输入框变化的函数
setMessages, // 手动设置消息列表的函数
isLoading, // 是否正在加载(等待 AI 响应)
reload: handleRetry, // 重试最后一条消息的函数(重命名为 handleRetry)
append, // 追加新消息到消息列表的函数
} = useChat({
// 后端 API 路由地址
api: "/api/vercelai",
// 错误处理回调函数
onError: (error) => {
console.error(error);
// 如果最后一条消息是用户消息,则去掉最后一条消息
// 这样可以在出错时回退到错误发生前的状态
setMessages((messages) =>
messages.length > 0 && messages[messages.length - 1].role === "user"
? messages.slice(0, -1)
: messages,
);
},
// 实验性功能:节流时间(毫秒),用于控制流式输出的更新频率
experimental_throttle: 100,
});
// 用于存储用户上传的图片 URL
// 当用户上传图片时,会与文本一起发送给 AI
const [messageImgUrl, setMessageImgUrl] = useState("");
/**
* 处理表单提交
* 创建新的用户消息并发送给后端 API
* 支持纯文本消息和带图片的消息
*/
const handleSubmit = async () => {
// 构建新的用户消息对象
const newUserMessage = {
id: nanoid(), // 生成唯一 ID
role: "user", // 消息角色为用户
// 如果有图片,则构建包含图片和文本的内容数组
// 如果没有图片,则直接使用文本内容
content: messageImgUrl
? [
{ type: "image_url", image_url: { url: messageImgUrl } },
{ type: "text", text: input },
]
: input,
};
// 将新消息追加到消息列表,触发 API 调用
append(newUserMessage as Message);
// 清空输入框
handleInputChange({
target: { value: "" },
} as React.ChangeEvent<HTMLInputElement>);
// 清空图片 URL
setMessageImgUrl("");
};
return (
<ChatMessages
// 将消息列表转换为组件所需的格式
messages={messages.map((msg: Message) => ({
id: msg.id,
role: msg.role as "user" | "assistant",
content: msg.content,
// 从消息的 annotations 中提取 RAG 相关文档
// annotations 是 Vercel AI SDK 提供的扩展字段,用于存储额外信息
ragDocs:
Array.isArray(msg.annotations) && msg.annotations[0]
? (
msg.annotations[0] as unknown as {
relevantContent: RAGDocument[];
}
).relevantContent
: undefined,
}))}
input={input}
handleInputChange={handleInputChange}
onSubmit={handleSubmit}
isLoading={isLoading}
messageImgUrl={messageImgUrl}
setMessagesImgUrl={setMessageImgUrl}
// 重试函数,用于重新发送失败的消息
onRetry={handleRetry as (id: string) => void}
/>
);
};
export default Home;效果展示
查看 RAG Docs:
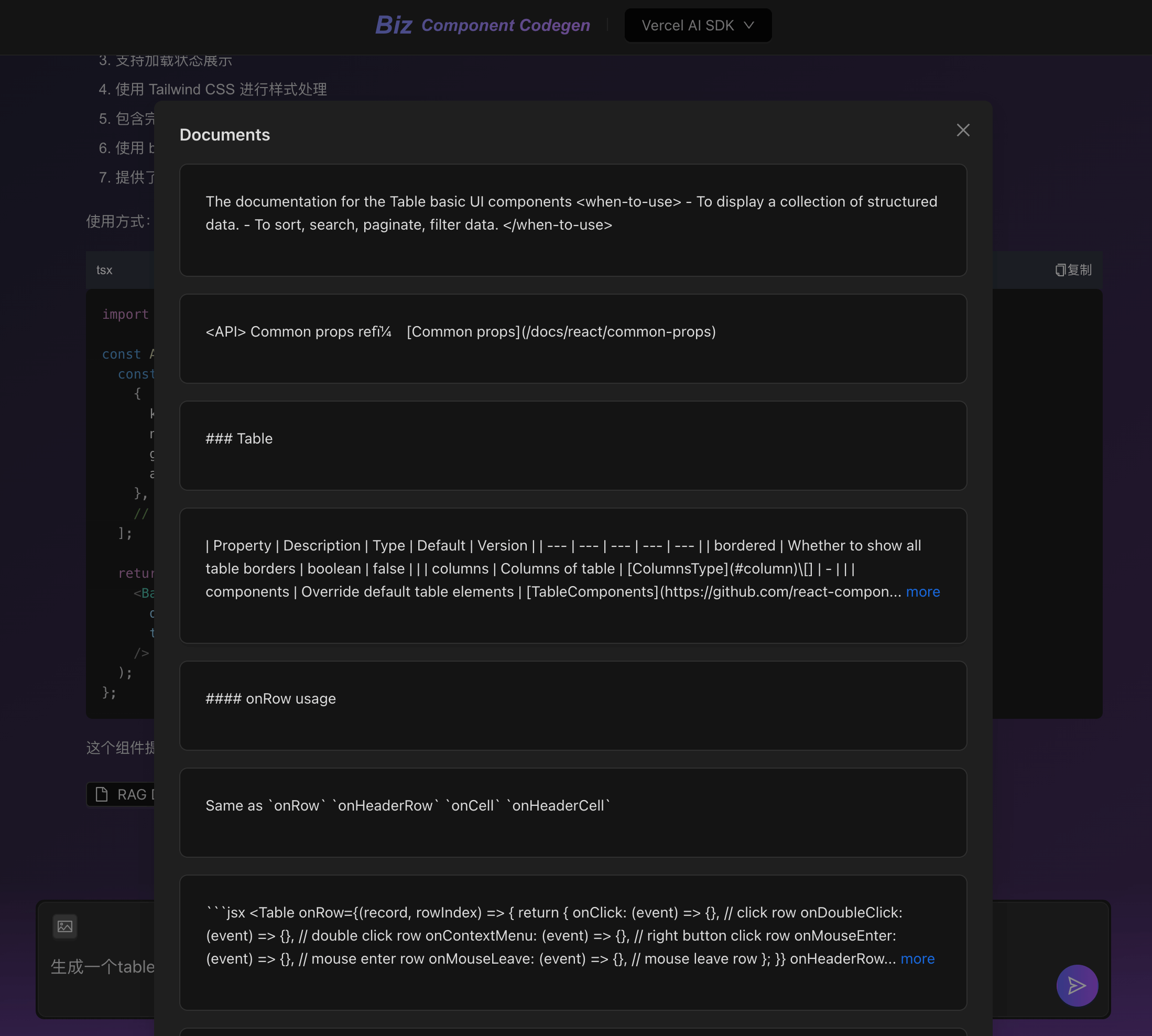
如何渐进式地在公司落地这套架构
对于迭代已有稳定业务来说
不建议改动,除非你能直接或间接推动公司决定针对整体的研发流程进行整体的 “AI 规范化重构”。
对于新的业务来说
1、针对 AI 友好的:剥离服务端状态和前端状态。
2、针对 整洁的:如果公司原有的业务组件结构已经很清晰,针对新的业务组件可以继续沿用。
如果不清晰或者没有规范,就可以采用本文中的这套。